A poor man's guide to fine-tuning Llama 2
Last Friday, Kostas and I found ourselves discussing AI over beers again. He was telling me how he thinks everyone else is decades away from OpenAI - and that they likely won't catch up soon. I disagreed. In fact, I think open source is quickly catching up, and getting closer by the day.
Around four months ago, I wrote a small tutorial on fine-tuning Flan T5 to generate conversations in my friends group chat. It worked ok(ish), but the process was clunky and took way too long.
So, here we are, four months later, with the same question: How easy is it to train an LLM on my friend's group chat? Turns out, for a couple of dollars and one hour you can get pretty far.
Data
The goal is clear: fine-tune Llama 2, to automatically generate conversations that would normally happen in the group chat that I've held with my close friends for years now. The first step is to export the data from Telegram (which is pretty easy).
For most LLMs, you need to massage the data into a specific format before training. This means providing things like the instruction, the input, the system_prompt, etc. But all I wanted was to generate conversations, so I started by creating a large jsonl file with chunks of conversations separated by a ### token to indicate the speaker.
# dataset.jsonl
{"text": "### Friend 1: This is a question### Friend 2: This is a reply### Friend 3: What the hell are you guys talking about?"}
{"text": "### Friend 4: Who's coming tonight?### Friend 2: No one, it's literally Monday."}
#...
After getting the data ready, I went ahead and pushed it to the hugging face hub:
# huggingface-cli login --token hf_XXXXXXXX (to log into Hugging Face)
# read and split
tiger_llama = pd.read_json('dataset.jsonl', lines=True)
train_tiger, test_tiger = train_test_split(
tiger_llama, test_size=0.15, random_state=42, shuffle=True
)
# push to hub
train_tiger = Dataset.from_pandas(train_tiger)
test_tiger = Dataset.from_pandas(test_tiger)
ds = DatasetDict()
ds["train"] = train_tiger
ds["test"] = test_tiger
dataset_name = "duarteocarmo/tiger-llama"
ds.push_to_hub(dataset_name, branch="main", private=True)
With all the conversations pushed to the hub (cough - privacy - cough), it was now time to train this model.
Training with axolotl
For the first couple of days, I got a bit frustrated. I tested a bunch of different tutorials on how to fine tune LLama-2. But none of them really got me anywhere. Some took way too long to train, others resulted in a model that didn't really generate anything interesting. I confess I almost fell to the dark side! But then I stumbled upon axolotl.
Axolotl is designed to "streamline the fine-tuning of LLMs". It supports a bunch of different models and training configurations. The best part? To fine-tune a model, all you is pretty much a config file. Yes, you heard that right - just a yaml file. The only things I needed to tweak were the base model (in our case, Llama 2 - meta-llama/Llama-2-7b-hf), and the dataset sections:
# llama-tiger.yaml
# base model
base_model: meta-llama/Llama-2-7b-hf
base_model_config: meta-llama/Llama-2-7b-hf
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
# ...
# my dataset
# other formats: https://github.com/OpenAccess-AI-Collective/axolotl#dataset
datasets:
- path: duarteocarmo/tiger-llama
type: completion #
field: text
dataset_prepared_path: last_run_prepared
hub_model_id: duarteocarmo/tiger-llama
val_set_size: 0.01
output_dir: ./qlora-out
# wandb monitoring
wandb_project: "llama-tiger"
wandb_log_model: "checkpoint"
### ...
Expand for the full tiger-llama.yaml file
# Image: winglian/axolotl:main-py3.10-cu118-2.0.1
base_model: meta-llama/Llama-2-7b-hf
base_model_config: meta-llama/Llama-2-7b-hf
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: duarteocarmo/tiger-llama
type: completion
field: text
dataset_prepared_path: last_run_prepared
hub_model_id: duarteocarmo/tiger-llama
val_set_size: 0.01
output_dir: ./qlora-out
adapter: qlora
lora_model_dir:
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: "llama-tiger"
wandb_entity:
wandb_watch:
wandb_run_id:
wandb_log_model: "checkpoint"
gradient_accumulation_steps: 4
micro_batch_size: 2
num_epochs: 3
optimizer: paged_adamw_32bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
eval_steps: 20
eval_table_size: 5
save_steps:
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"
Unfortunately, with these things, I needed a GPU to run the training. Given that I'm (apparently) considered GPU poor, I used Vast.ai. I got a machine with at least ~40GB of GPU RAM, and that was relatively close to me. These cost around 1 USD/hour. I also used the Axololt docker image (e.g., winglian/axolotl:main-py3.10-cu118-2.0.1) so that everything was pre-installed when the machine turned on.
Once the machine was up, I ssh'd into it and ran:
$ huggingface-cli login --token hf_MY_HUGGINGFACE_TOKEN_WITH_WRITE_ACCESS
$ wandb login MY_WANDB_API_KEY
$ accelerate launch -m axolotl.cli.train llama-tiger.yaml
And we were off to the races. With a single command, I was fine-tuning Llama 2 on my custom dataset. While training, Axolotl automatically logs everything to Weights & Biases, so we can monitor how the losses are evolving. As a bonus, it also shows the model outputs so that I can follow how to model is improving its generation during training:
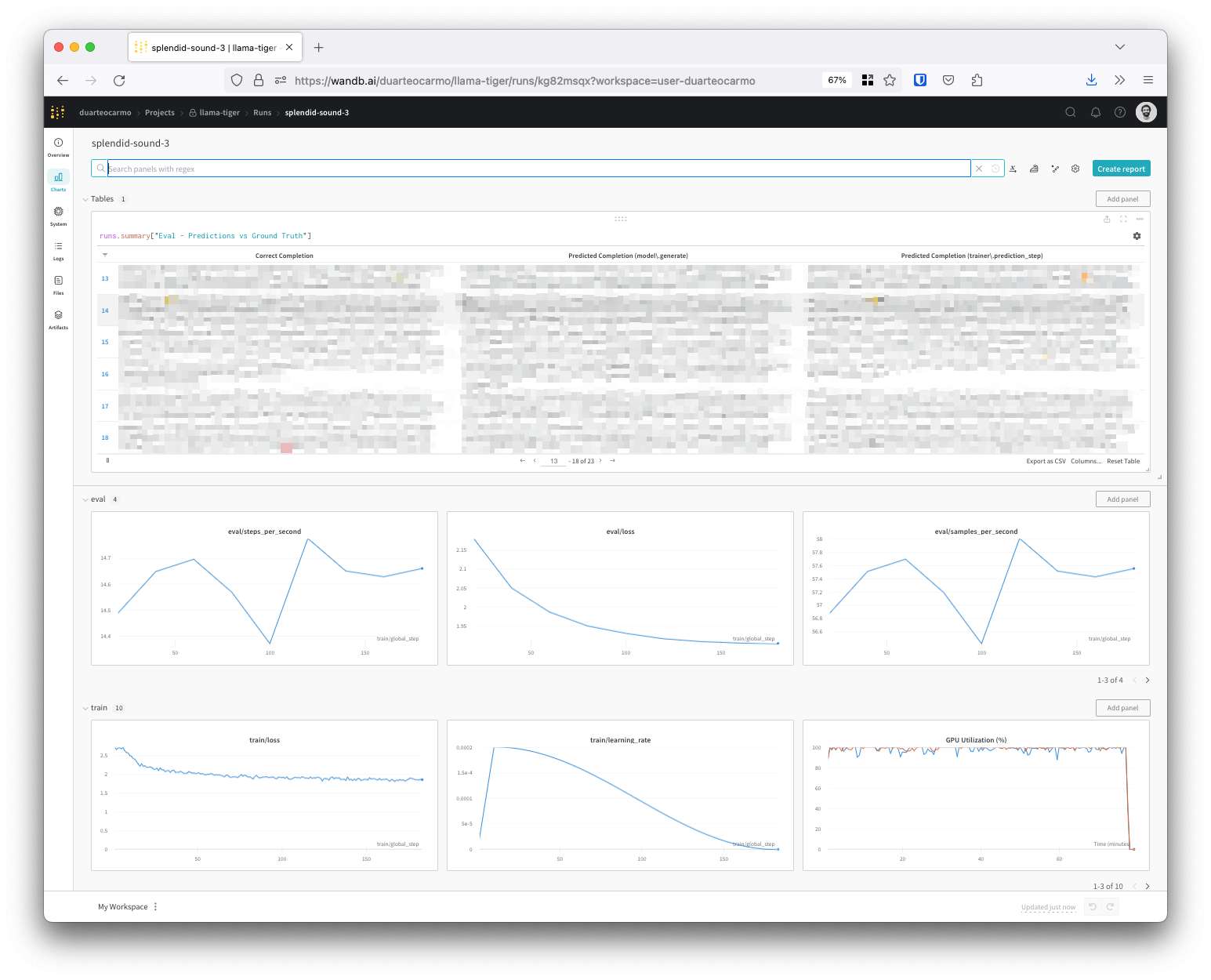
My dataset has ~12K rows. Training took around 1 hour in total, using a machine with 2xA40 GPUs. In summary: I spent around 2 USD to fine-tune the whole model.
Once training was done, your fine-tuned model (or adapter, to be specific) is saved in the ./lora-out directory. With my configuration, it was also uploaded the model to the hugging face repository I provided in hub_model_id. Onto the inference.
Inference
The fine-tuning result is not an actual Llama 2 model, but an adapter to the model (Axolotl uses qlora by default for Llama models). So in the end, the adapter is a mere 320 MB.
Using Axolotl, inference is also pretty straightforward: All I need to do is download the model, and launch the Axolotl inference command:
# download from fine tuned repo
git lfs install
git clone https://huggingface.co/duarteocarmo/tiger-llama
# run axolotl inference
accelerate launch -m axolotl.cli.inference tiger-llama.yaml --lora_model_dir="./tiger-llama"
Once downloaded and launched, I can give the model the start of a fake conversation, and it will go on to generate a completely fake conversation based on my group chat:
Input: ### SZ: Quem vem a Lisboa no natal?
Output: ### SZ: Quem vem a Lisboa no natal?### PK: Acho que tenho tive uma surpresa de aniversario da malta, não tenho férias até janeiro### SZ: Fodass, faltamos 2 ...
Closing thoughts
Compared to the last time I fine-tuned a model, open source is definitely moving fast. The process was not only much faster, and simpler than fine-tuning Flan T5 using a notebook, but the results were also much better than anything I had seen so far.
Axolotl did almost all the heavy lifting. Making the whole process super smooth. All I needed was a dataset, a config file, 2 USD, and about an hour to fine-tune a model. We've come a long way.
The model is still not perfect though. It captures some of my friends' quirks and ways of speaking, and the generated conversations make sense around ~70% of the time. But that's still 30% nonsense. Could be a couple of things: the size (I used the "smaller" 7 billion version of the model), or even the language (Portuguese from Portugal). For example, when I prompt the model to simulate a politics discussion between my friends, someone starts discussing something about Dilma (which is wildly inaccurate given we're from Portugal).
So Kostas was right, "open source" hasn't caught up yet. But oh boy, we're getting damn close.