Fine-tuning FLAN-T5 to replace my friends
They say that the best way to learn about something is to build it yourself. Everyone talks about OpenAI this, and OpenAI that. How about we fine tune a Large Language Model ourselves?
If you heard about this models before, but are still curious about how all of these things work underneath, this blog post is just for you. With it, you'll learn how to fine tune a Large Language Model (Google's FLAN-T5) on the conversation history of a group chat you have lying around. The goal is to teach the model to talk exactly like your friends would. It won't be perfect, of course, but the goal here is to learn how these things work.
Here's how we'll structure things:
- Why FLAN-T5
- Setting up your environment
- Preparing the data
- Fine-tuning the model
- Generating conversations
Even though I love taking credit for ideas that are not mine, this blog post was inspired by the work of some other awesome folks. Particularly this one, and this one.
Let's get started.
1. Why FLAN-T5
There are a lot of Large Language Models (e.g., LLMs) out there. With the explosion of things like GPT-3 and GPT-4, lots of companies and open source organizations have started building their own LLMs. Some of these models leaked, others are powerful but only available through an API.
Some of theses LLMs that are actually free an open source, even for comercial use. Eugene Yan, has compiled a great repo with an outline of some of these options.
In 2020, Google released a paper called "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer", where they presented their T5 model. T5 is a encoder-decoder model that was trained in a variety of tasks (e.g., translate to german, summarize the following sentence, etc). FLAN-T5 is basically the exact same thing as T5, but pretty much better at everything it does.
There are a couple of other reasons why we're using Flan-T5 for this guide:
- It's free, open source, and commercially available
- It has several sizes we can use (from small, all the way to xxl)
- It's compatible with the whole Hugging Face 🤗 ecosystem, making our life easier
With that. Let's get things started.
2. Setting up the environment
Note: This tutorial was run on a NVIDIA A100 with 40GB of RAM
If you want to run this project but don't have a powerful GPU at hand, you can get started quickly using Unweave. After signing up and installing, you can launch this project in two steps:
# link this repo to your unweave account
!unweave link your-username/fine-tune-llm
# launch a machine powered by a A100 GPU
!unweave code --new --type a100 --image pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel
Also, to save and load models, you'll need to have a Hugging Face account. Once you have that set up, create and copy a new token. Paste it somewhere, we'll need it for later.
The following cell, will install all required python libraries, as well as some local packages we'll need. (e.g., git, git-lfs)
!pip install pytesseract evaluate tqdm transformers datasets rouge-score accelerate nltk tensorboard jupyter-black py7zr --upgrade
!apt-get install git --yes
!apt-get install git-lfs --yes
Take your Hugging Face token, and replace it with in the field below. This will log you into the Hugging Face hub, which we'll need to push and pull models.
!huggingface-cli login --token XXXXXXXXXXXXXXXX
3. Data preprocessing
Let' start by preprocessing our data for training. We'll start by defining some variables. Feel free to replace the location of your Telegram group chat export in the TELEGRAM_EXPORT variable:
import json
import pandas
import jupyter_black
from datetime import timedelta
from datasets import Dataset
jupyter_black.load()
TELEGRAM_EXPORT = "anonym_telegram.json" # anonymized for obvious reasons
CONVERSATION_LIMIT = 20_000 # limit number of messages
TEST_SIZE = 0.2 # % of test data
IS_NEW_SESSION_CUTOFF_MINS = (
120 # if the time between messages is more than this, it's a new session
)
Let's preprocess this into a dataframe:
# load data in
with open(TELEGRAM_EXPORT, "r") as f:
data = json.load(f)
messages = data["messages"]
# create a dataframe
df = pandas.DataFrame(messages)[["text", "from", "date"]]
# filter empty messages
df = df[df["from"].isna() == False]
df = df[df["text"].isna() == False]
df = df[df["text"].str.len() > 0]
df["date"] = pandas.to_datetime(df["date"]) # convert to datetime
df.sort_values("date", inplace=True) # sort by date
df = df.tail(CONVERSATION_LIMIT) # limit number of messages
Now, the goal is to get our data into a format where the model can understand the conversation, and respond to what has been going on. Something like:
{
"conversation": "Person X: Where were you yesterday?\nPerson Y: I was at home! You?",
"response": "Person X: Me too, but thought of going out."
}
This will allow the model to see a thread and respond in the most realistic manner possible to the conversation that was already going on.
However, we also know that group chats are pretty async, so we don't necessarily want a "good morning" message to be a direct response to whatever happened last night.
# telegram exports have some artifacts, let's clean them up
def clean_text(text: str) -> str:
if isinstance(text, list):
text = "".join([o.get("text", o) if isinstance(o, dict) else o for o in text])
return text
# clean up and rename columns
df["text"] = df["text"].apply(clean_text)
df["chat"] = "telegram"
df.rename(
columns={"from": "sender", "date": "message_date", "text": "response"}, inplace=True
)
# create new sessions
df["last_event"] = df.groupby("chat")["message_date"].shift(1)
df["is_new_session"] = (
(df["message_date"] - df["last_event"]).fillna(
pandas.Timedelta(minutes=IS_NEW_SESSION_CUTOFF_MINS)
)
>= timedelta(minutes=IS_NEW_SESSION_CUTOFF_MINS)
).astype(int)
df["chat_session_id"] = (
df.sort_values(["chat", "message_date"]).groupby("chat")["is_new_session"].cumsum()
)
Now that we have everything setup, it's time to create a conversation column, that has all the messages before a certain response:
sess_dict = df.to_dict("records")
items = []
counter = 0
for row in sess_dict:
context = []
cstring = ""
for i in range(10, 0, -1):
if sess_dict[counter - i]["chat_session_id"] == row["chat_session_id"]:
msg = (
f"{sess_dict[counter-i]['sender']}: {sess_dict[counter-i]['response']}"
)
if len(context) > 0:
cstring += "\n"
context.append(msg)
cstring += msg
if len(context) < 2:
for i in range(5, 0, -1):
msg = (
f"{sess_dict[counter-i]['sender']}: {sess_dict[counter-i]['response']}"
)
context.append(msg)
cstring += "\n"
cstring += msg
items.append(cstring)
counter += 1
# create the conversation column
df["conversation"] = items
# create the response column
df["response"] = df.apply(lambda row: f"{row.sender}: {row.response}", axis=1)
print(f"Your dataframe shape is {df.shape}")
print(f"You have the following columns: {', '.join(df.columns.tolist())}")
# Your dataframe shape is (20000, 8)
# You have the following columns: response, sender, message_date, chat, last_event, is_new_session, chat_session_id, conversation
Let's see what a single example looks like:
item = df.sample(1, random_state=314)[["conversation", "response", "sender"]].to_dict(
"records"
)[-1]
print(f"Conversation:\n{item['conversation']}\n")
print(f"Response:\n{item['response']}\n")
# Conversation:
# Hugo Silva: Lembram se do meu amigo alex frances?
# Tiago Pereira: Claro ya
# Hugo Silva: Ele correu a maratona de paris outra vez..
# Tiago Pereira: E…
# Tiago Pereira: Ou é só isso?
# Hugo Silva: Numero 304 overall...
# Hugo Silva: Crl
# Tiago Pereira: Eia cum crlh
# Hugo Silva: Pa doente
# Tiago Pereira: 3’46. Que louco fds
#
# Response:
# Hugo Silva: Doente completo
Our final preprocessing step is to load our dataframe in the Datasets format:
cols_for_dataset = ["conversation", "response"]
df = df[cols_for_dataset]
data = Dataset.from_pandas(df).train_test_split(test_size=0.2)
print(data)
# DatasetDict({
# train: Dataset({
# features: ['conversation', 'response', '__index_level_0__'],
# num_rows: 16000
# })
# test: Dataset({
# features: ['conversation', 'response', '__index_level_0__'],
# num_rows: 4000
# })
# })
Great. We're ready to focus on the model.
4. Fine-tuning the model
We start with some training specific imports, mostly related to Hugging Face.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from datasets import concatenate_datasets
import evaluate
import nltk
import numpy as np
from nltk.tokenize import sent_tokenize
from transformers import DataCollatorForSeq2Seq
from huggingface_hub import HfFolder
from transformers import pipeline
from random import randrange
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
import os
Now, we define the most important variables for training, make sure to read the description of each one:
MODEL_NAME = "chat" # the name of your model
MODEL_ID = "google/flan-t5-small" # the id of the base model we will train (can be small, base, large, xl, etc.) (the bigger - the more GPU memory you need)
REPOSITORY_ID = f"{MODEL_ID.split('/')[1]}-{MODEL_NAME}" # the id of your huggingface repository where the model will be stored
NUM_TRAIN_EPOCHS = 4 # number of epochs to train
Let's load the model and the tokenizer with the help of AutoModelForSeq2SeqLM:
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_ID)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
Some samples in our dataset will likely be too long for our model. So they'll need to be truncated. In the cell below, we define the max conversation and response lenght. This will then help in the truncating process:
# source
tokenized_inputs = concatenate_datasets([data["train"], data["test"]]).map(
lambda x: tokenizer(x["conversation"], truncation=True), batched=True
)
max_source_length = max([len(x) for x in tokenized_inputs["input_ids"]])
# target
tokenized_targets = concatenate_datasets([data["train"], data["test"]]).map(
lambda x: tokenizer(x["response"], truncation=True), batched=True
)
max_target_length = max([len(x) for x in tokenized_targets["input_ids"]])
print(f"Max source length: {max_source_length}")
print(f"Max target length: {max_target_length}")
Now that we know the limit for the truncation, we'll preprocess our dataset to be fed into the model. During its original training, FLAN T5 used different templates for training on multiple tasks. Here, I decided to use the Continue writing the following text template. I did not test all of them, so feel free to modify according to what suits your task best.
def preprocess_function(sample, padding="max_length"):
template_start = "Continue writing the following text.\n\n"
inputs = [template_start + item for item in sample["conversation"]]
model_inputs = tokenizer(
inputs, max_length=max_source_length, padding=padding, truncation=True
)
labels = tokenizer(
text_target=sample["response"],
max_length=max_target_length,
padding=padding,
truncation=True,
)
if padding == "max_length":
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label]
for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_dataset = data.map(
preprocess_function, batched=True, remove_columns=["conversation", "response"]
)
print(f"Keys of tokenized dataset: {list(tokenized_dataset['train'].features)}")
Let's define some metrics for the evaluation of the model:
# metric
metric = evaluate.load("rouge")
nltk.download("punkt")
# postprocess text
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
preds = ["\n".join(sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(sent_tokenize(label)) for label in labels]
return preds, labels
# compute metrics
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(
predictions=decoded_preds, references=decoded_labels, use_stemmer=True
)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [
np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds
]
result["gen_len"] = np.mean(prediction_lens)
return result
Our final data preparation step is to use DataCollatorForSeq2Seq to handle the padding for inputs and labels:
label_pad_token_id = -100
data_collator = DataCollatorForSeq2Seq(
tokenizer, model=model, label_pad_token_id=label_pad_token_id, pad_to_multiple_of=8
)
Finally, we can define the training arguments. Feel free to play around with these. Depending on the use case, results can vary!
# Define training args
training_args = Seq2SeqTrainingArguments(
# training parameters
output_dir=REPOSITORY_ID,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
predict_with_generate=True,
fp16=False, # Overflows with fp16
learning_rate=5e-5,
num_train_epochs=NUM_TRAIN_EPOCHS,
# logging & evaluation strategies
logging_dir=f"{REPOSITORY_ID}/logs",
logging_strategy="steps",
logging_steps=500,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
# push to hub parameters
report_to="tensorboard",
push_to_hub=False,
hub_strategy="every_save",
hub_model_id=REPOSITORY_ID,
hub_token=HfFolder.get_token(),
disable_tqdm=False,
)
# Create Trainer instance
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
compute_metrics=compute_metrics,
)
Now, we can kick-off training! This can take ~20 mins if you use the small model, or about a couple of hours with the base model. Of course, this largely depends on how much data you have, what's your GPU, epochs, etc. Feel free to tweak the params above to your liking!
# Start training
trainer.train()
Once training is done, we can now push things to the hub!
tokenizer.save_pretrained(REPOSITORY_ID)
trainer.create_model_card()
trainer.push_to_hub()
tokenizer.push_to_hub(REPOSITORY_ID)
5. Generating conversations
Now, generation with these models can be quite a challenge. OpenAI for example, used RLHF to align these models, and reward them for generating nice outputs. Here's a great sketch that illustrates the importance of the different training steps:
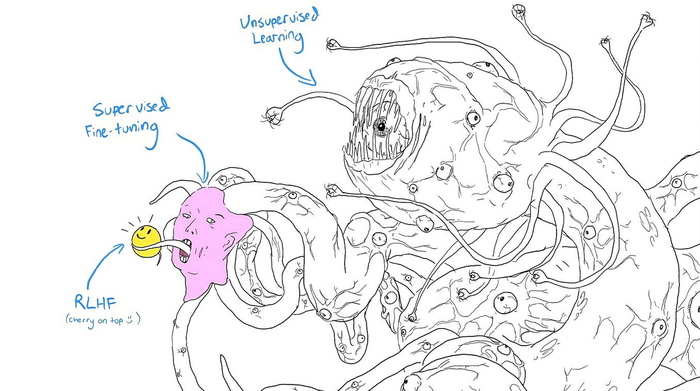
In our use case, there are some parameters we can leverage when generating text. In this article, Patrick Von Platen goes through the different techniques & methods we can use to control the output of these models.
There are quite a few parameters you can tweak:
- Either you are using greedy or beam search
- Sampling
- Top-K sampling
- Top-P sampling
- Size of n-grams to not repeat
I advise you to go through the article and learn a bit about each one of these!
Context given, let's get to it:
import random
import torch
Let's first load the model we pushed to the hub. (You can also just use the directory where your model is saved instead.)
# load tokenizer and model
REPOSITORY_ID = "flan-t5-small-chat/checkpoint-8000/" # the name of your repository where the model was pushed
tokenizer = AutoTokenizer.from_pretrained(REPOSITORY_ID)
model = AutoModelForSeq2SeqLM.from_pretrained(REPOSITORY_ID)
# put model on GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = model.to(device)
To kick off the generation, we select a random converstaion in our dataset:
random.seed(502)
sample = random.choice(data["test"])
STARTING_TEXT = sample["conversation"]
print(STARTING_TEXT)
# Tiago Pereira: 12h EM PORTUGAL:
# Tiago Pereira: 2 votos por pessoa pfv.
# Hugo Silva: Nao é anonymous?
# Tiago Pereira: Não. Tudo visivel
# Luís Rodrigues: Foi uma bela administração sim senhor.
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# remember to learn and tweak these params
generation_params = {
"max_length": 600,
"no_repeat_ngram_size": 1,
"do_sample": True,
"top_k": 50,
"top_p": 0.95,
"temperature": 0.7,
"num_return_sequences": 1,
"repetition_penalty": 1.3,
}
encoded_conversation = tokenizer(STARTING_TEXT, return_tensors="pt").input_ids.to(
device
)
output_encoded = model.generate(encoded_conversation, **generation_params)
output_decoded = tokenizer.decode(output_encoded[0], skip_special_tokens=True)
print(f"Response:\n{output_decoded}")
# Response:
# Raul Carvalho: Mas é uma bela
Another fun thing to do, is to let the model generate conversations completely by himself.
The idea here is to:
- Start with a real conversation (5 replies)
- Generate a response using our model
- Create a new exchange (4 real replies + 1 AI generated)
- Generate a response
- Create a new exchange (3 real replies + 2 AI generated)
- etc..
Eventually, we'll end up with a bunch of AI generated conversations from our model! Here's the code to do that:
conversation = None
NUMBER_OF_ROUNDS = 5
for i in range(NUMBER_OF_ROUNDS):
if not conversation:
conversation = STARTING_TEXT
encoded_conversation = tokenizer(conversation, return_tensors="pt").input_ids.to(
device
)
output_encoded = model.generate(encoded_conversation, **generation_params)
output_decoded = tokenizer.decode(output_encoded[0], skip_special_tokens=True)
conversation = conversation + "\n" + output_decoded
conversation = "\n".join(conversation.split("\n")[1:]) # remove first intervention
print(f"New conversation:\n{conversation}\n----")
# New conversation:
# Tiago Pereira: 2 votos por pessoa pfv.
# Hugo Silva: Nao é anonymous?
# Tiago Pereira: Não. Tudo visivel
# Luís Rodrigues: Foi uma bela administração sim senhor.
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# Raul Carvalho: Ahaha
# ----
# New conversation:
# Hugo Silva: Nao é anonymous?
# Tiago Pereira: Não. Tudo visivel
# Luís Rodrigues: Foi uma bela administração sim senhor.
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# Raul Carvalho: Ahaha
# André Ferreira: Pa no estou?
# ----
# New conversation:
# Tiago Pereira: Não. Tudo visivel
# Luís Rodrigues: Foi uma bela administração sim senhor.
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# Raul Carvalho: Ahaha
# André Ferreira: Pa no estou?
# André Ferreira: No estou a caralhar
# ----
# New conversation:
# Luís Rodrigues: Foi uma bela administração sim senhor.
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# Raul Carvalho: Ahaha
# André Ferreira: Pa no estou?
# André Ferreira: No estou a caralhar
# André Ferreira: Ainda no estou?
# ----
# New conversation:
# Leonardo Soares: Obrigado a esta administração! Dinâmica, Pacífica, Estruturadora, Libertadora!
# Leonardo Soares: #XeJonnyLegislativas2026
# Leonardo Soares: (2026 right? 😅)
# André Ferreira: PORTUGAL HOJE
# Raul Carvalho: Ahahaha vamos!!!!
# Raul Carvalho: Ahaha
# André Ferreira: Pa no estou?
# André Ferreira: No estou a caralhar
# André Ferreira: Ainda no estou?
# Raul Carvalho: Haha nvel queres meeses
# ----