You also hate SQL? Let the LLM handle it
Last year I made an effort to speak less and learn more. However, I still had the opportunity to present at a couple of conferences. One of them was PyCon Wroclaw. The main goal was to talk about a couple of interesting paradigms I've come across while using LLMs to help me solve some Text-to-SQL problems.
Unfortunately the recording came out a bit broken. So I decided to copy a typical post from Simon's blog, and do a small slide walk through here. I won't promise I'll do this for the rest of my talks. But I think it could be a pretty interesting read.
I started with my typical introduction:


The goal of the talk was to walk through a 'grab bag' of client cases I've come across recently and five different lessons I've learned.

The first chapter was all about setting expectations right. When clients come with a problem nowadays, they always expect a "ChatGPT" style of product.

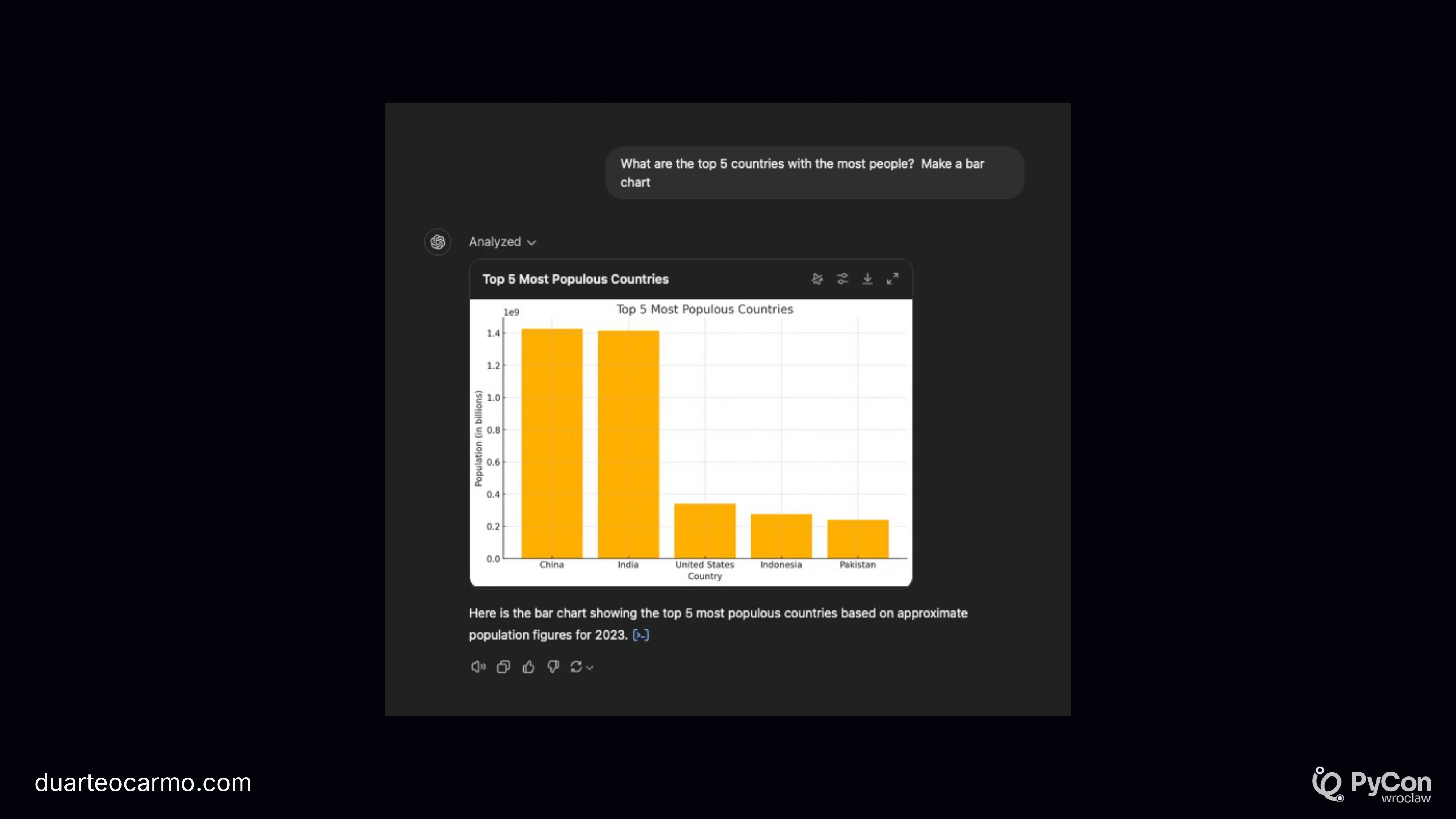
But ChatGPT isn't a simple product. It's actually a fairly complex piece of software.

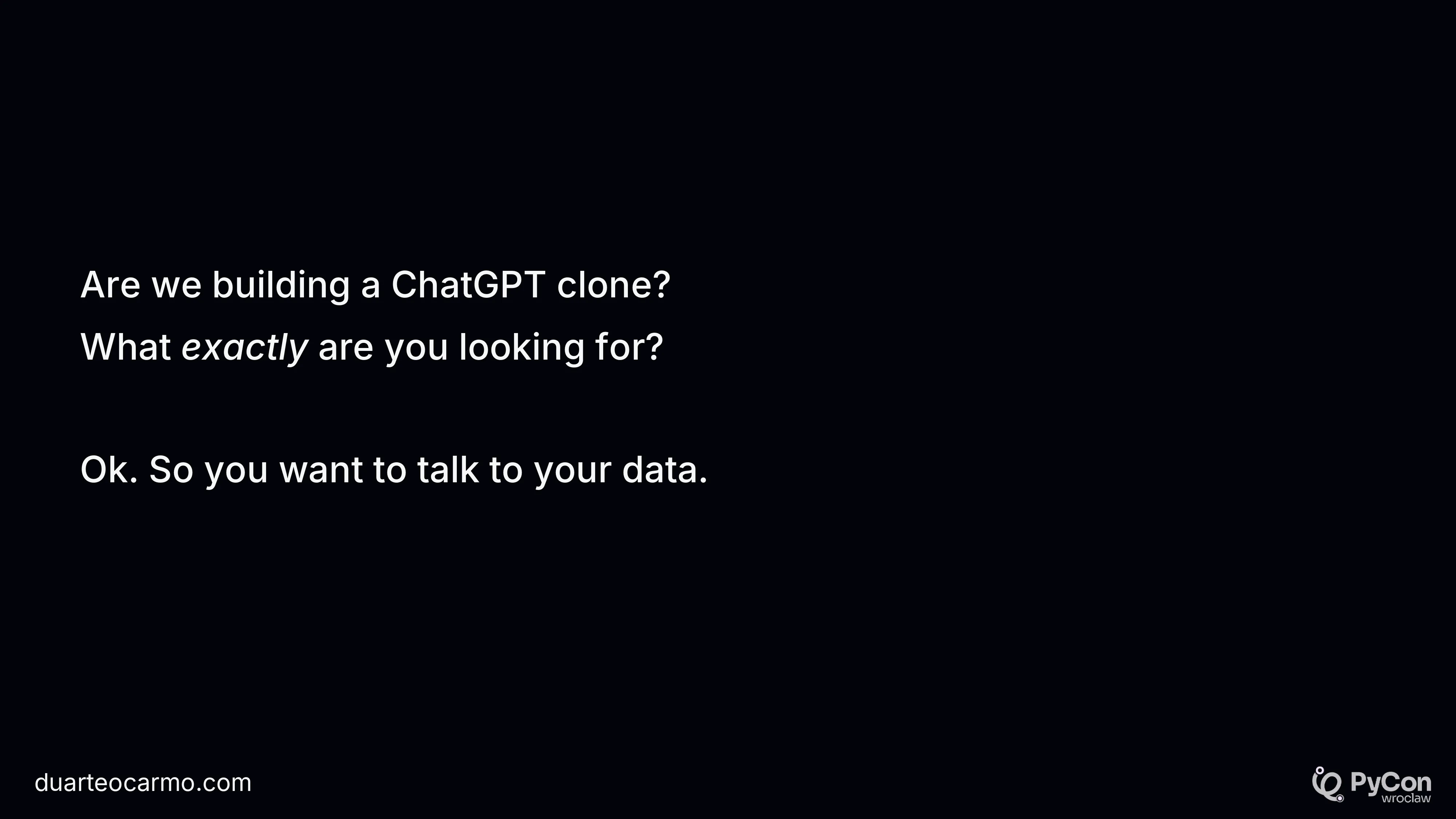
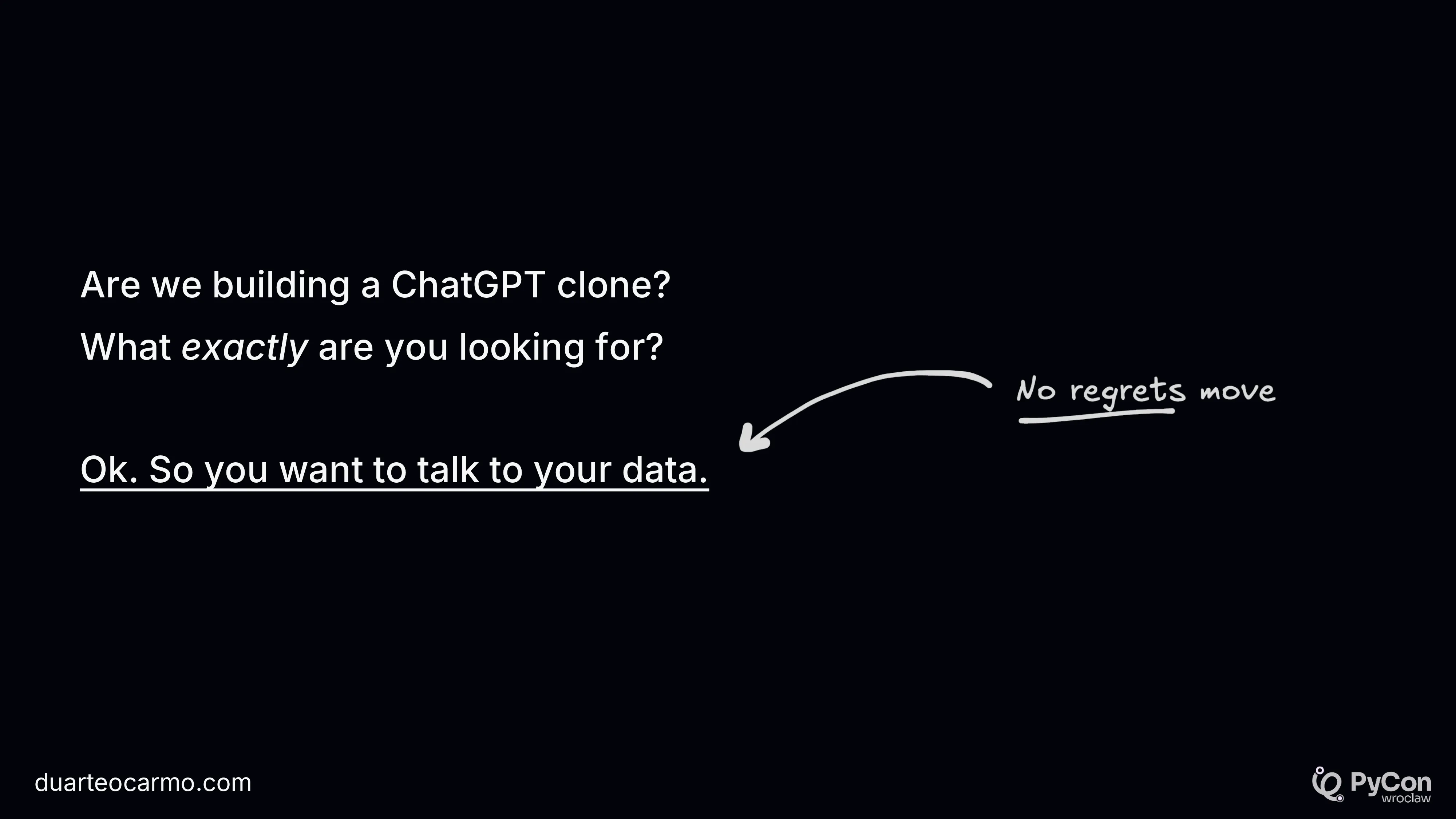
Here I introduced what I call the no regrets move. I.e., what is the minimum thing that you can solve for a certain problem that will always be valuable? In the case of text-to-sql, it's not the interface. It's just answering questions based on your data.
The second chapter was all about getting something out. Quick. I'm convinced that at least 50% of engineering problems are due to someone developing something in the basement instead of failing fast.


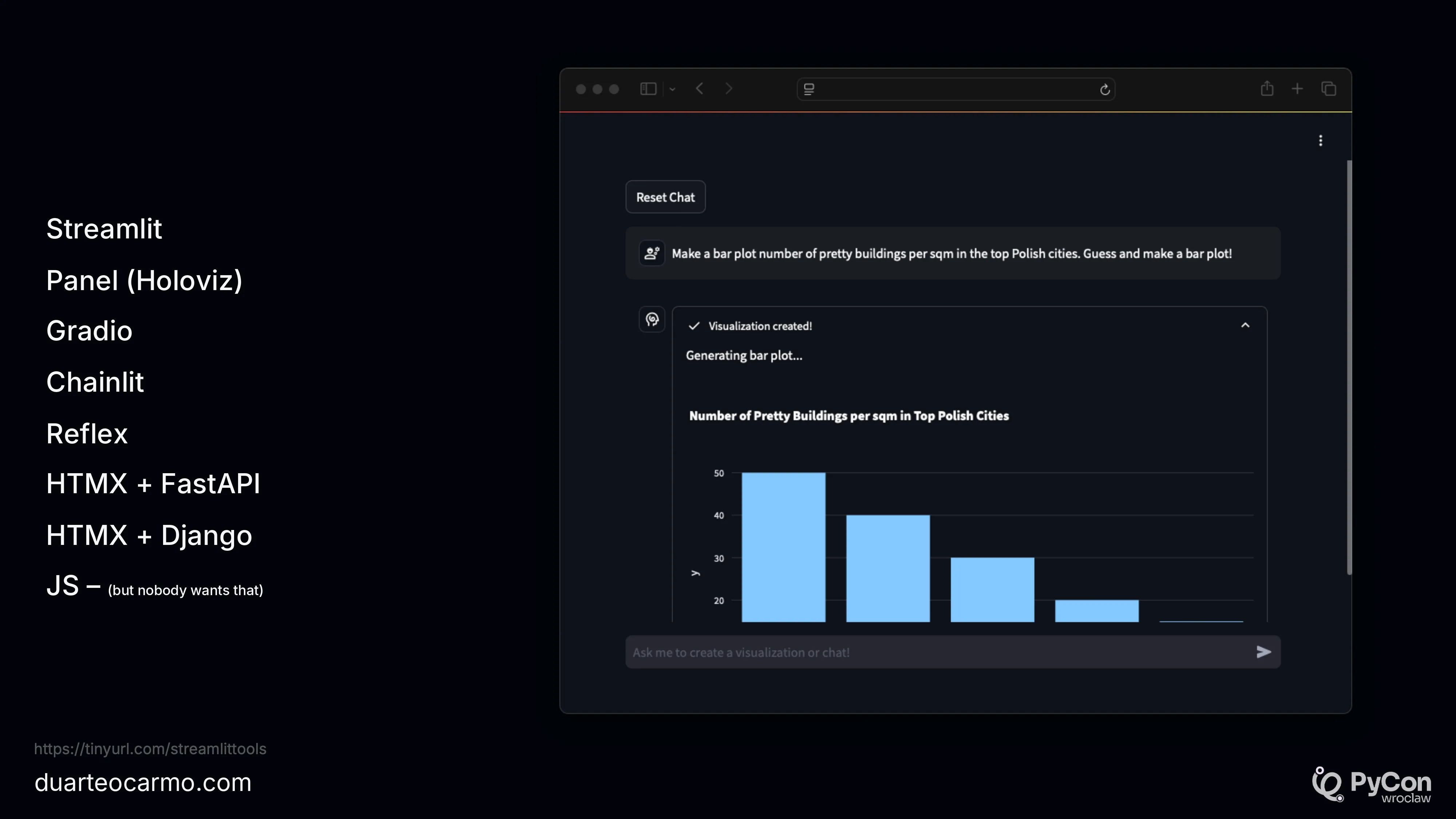
Here I mentioned some tools to get a ChatGPT interface relatively fast. So you can focus on what matters. Here's the code for a ChatGPT-like interface using Streamlit that already includes tools like plotting.
This is my favorite advice for any sort of engineering:

In the 3rd chapter I finally start focusing on the task at hand. Text-to-SQL.

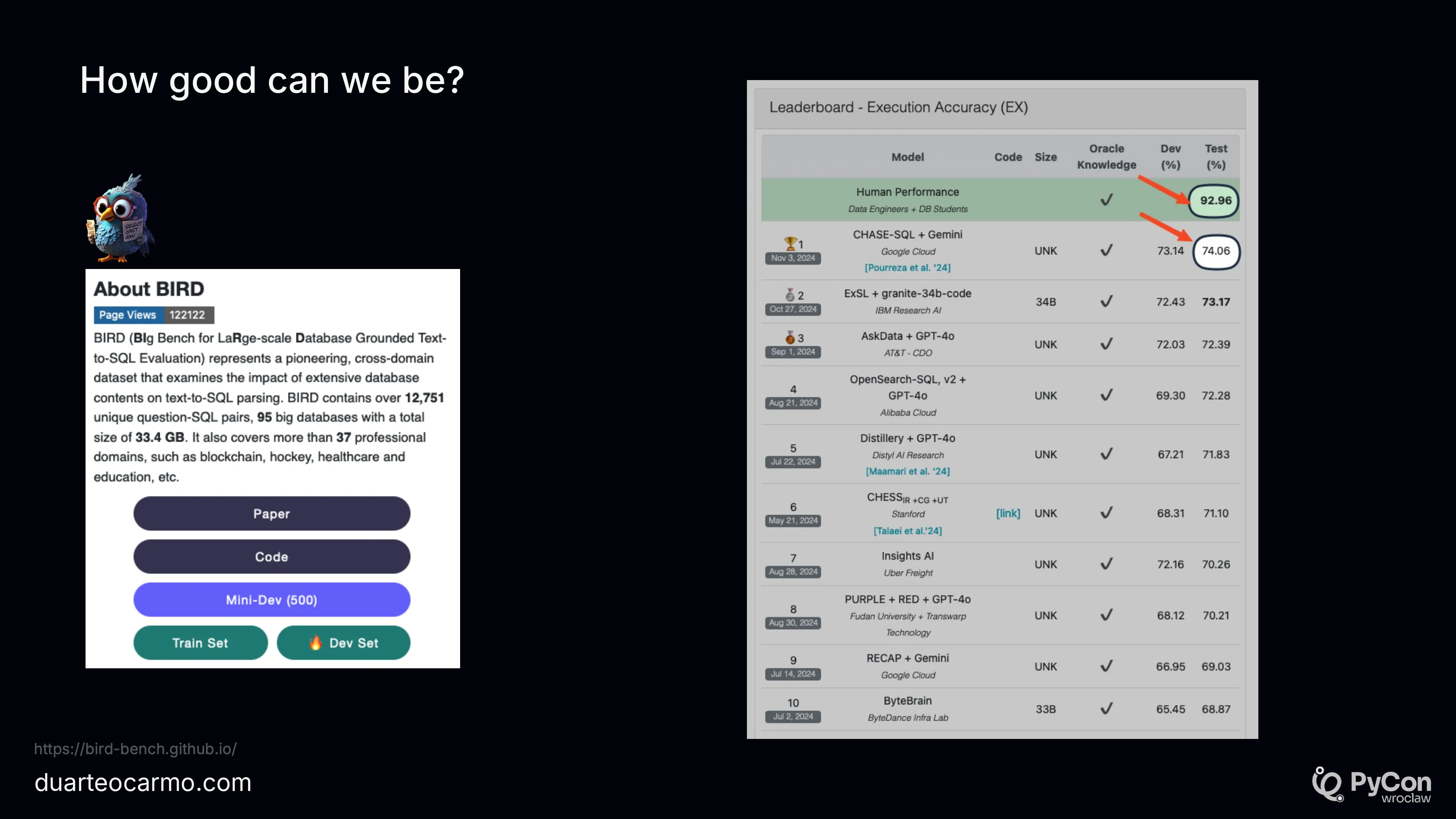
I took some time to present the BIRD-SQL benchmark. One of the most popular benchmarks for text-to-sql.

When looking at the rankings, we can see that the best performing text-to-sql system has an accuracy ~75%. So in your best case scenario. Whatever you build. You can already expect your LLM to get at least 1/4 questions wrong.

I cover two 'typical' approaches to text-to-sql. And how these approaches can go from something very simple in the right - just by stuffing information into the prompt. To something a bit more complex in the left.
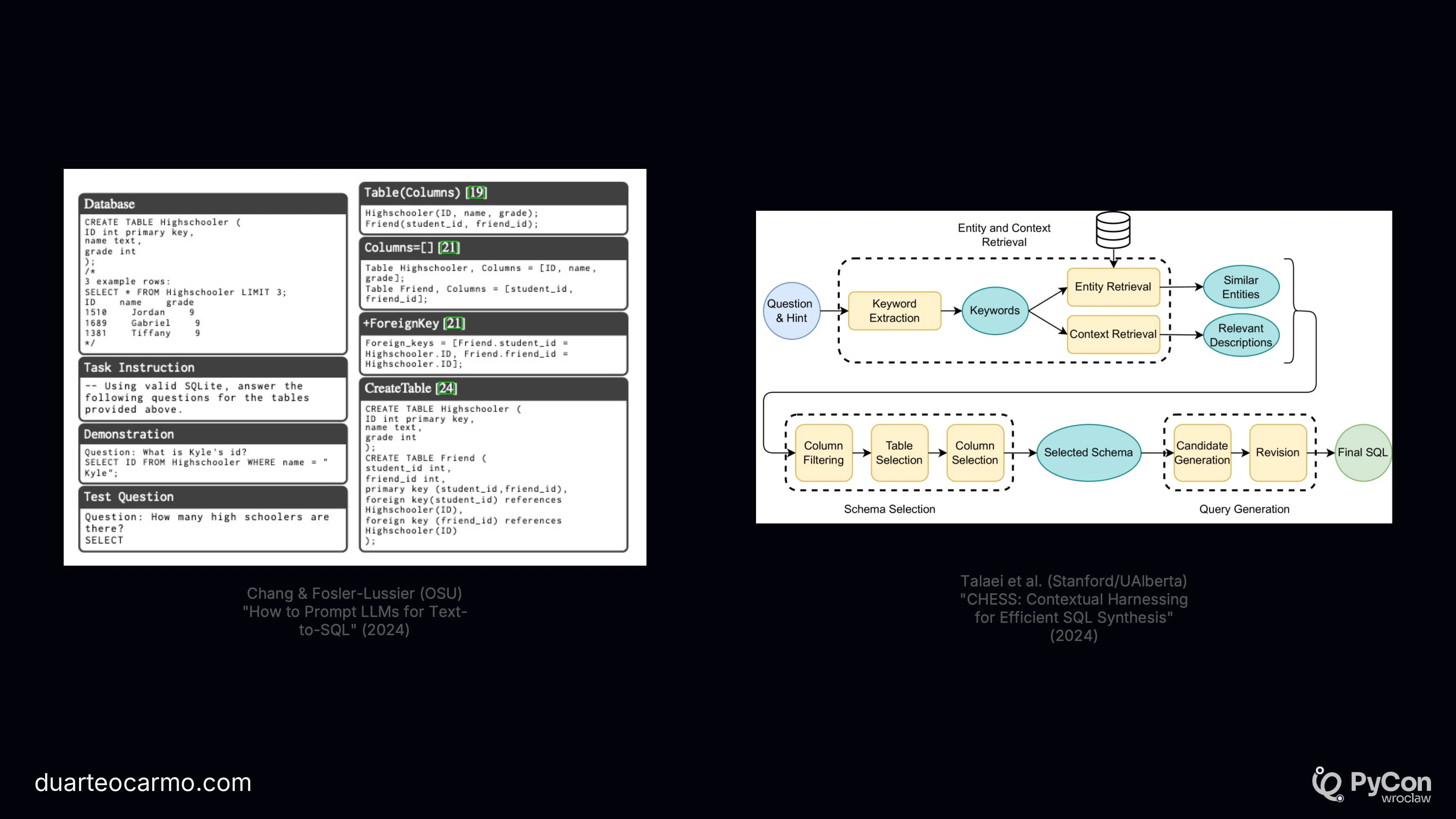
But in general. Stuffing information into the prompt is what most people are doing.

In the fourth chapter, I go into a good baseline to generate SQL to answer questions about a particular database.

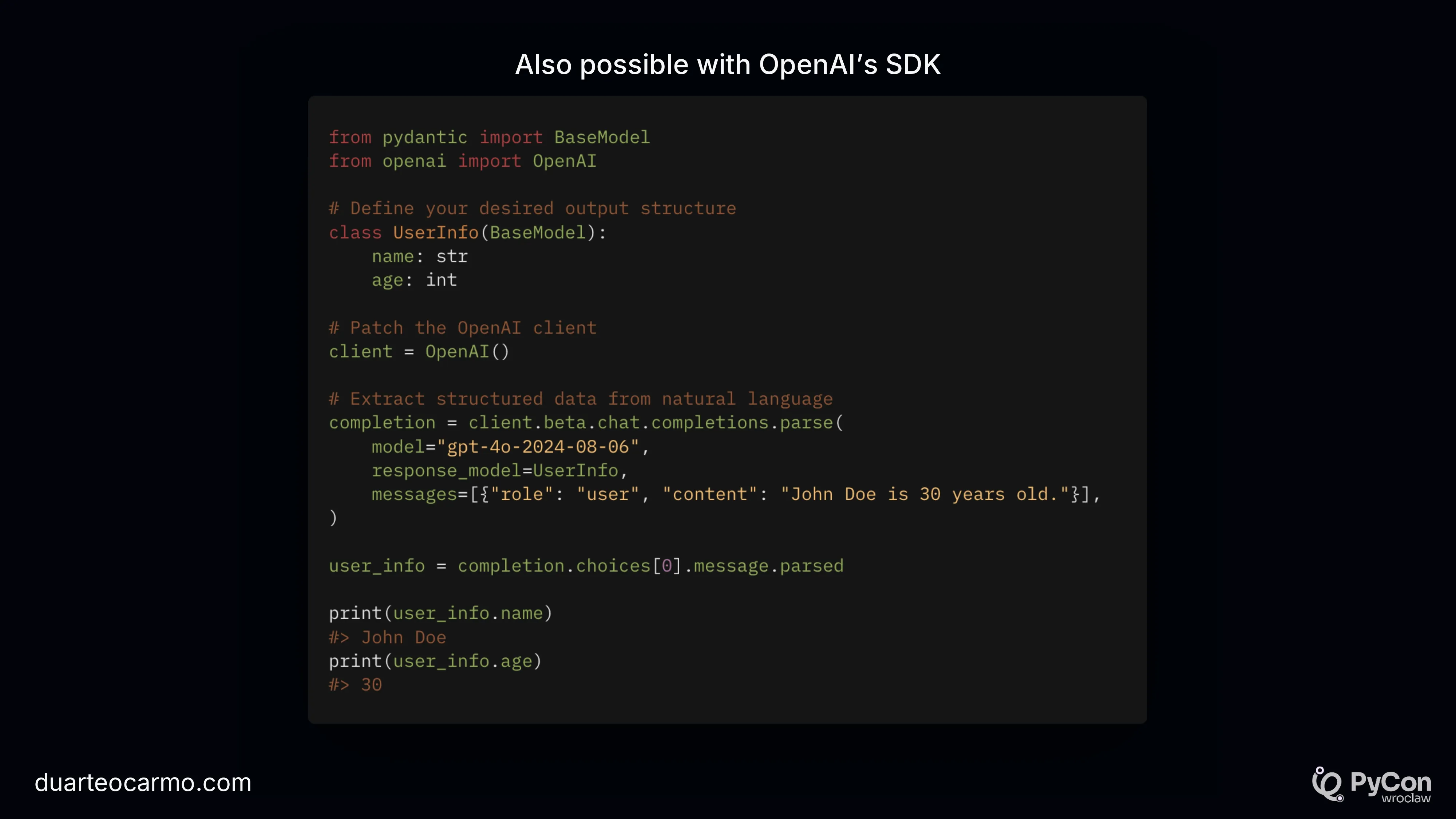
I start by talking about the funny 'please give me json' prompts. And show this small bit straight from one of Apple's prompts (Probably Apple Intelligence), where they beg the LLM to return json.
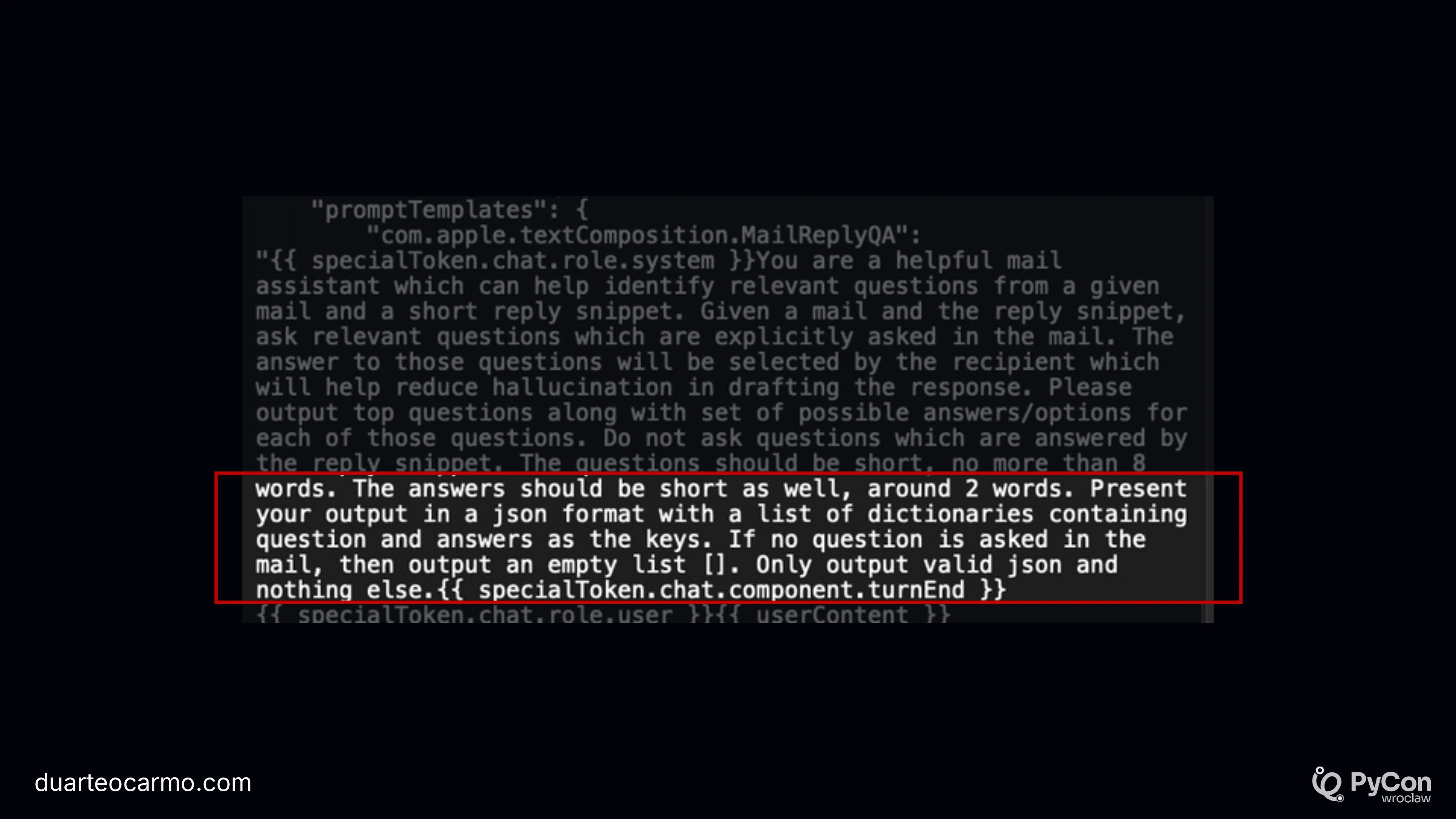
But for me, structured outputs are critical for a maintainable and well-built LLM application. So I also take some time to talk about that.

I start by introducing instructor, one of my favorite LLM libraries.
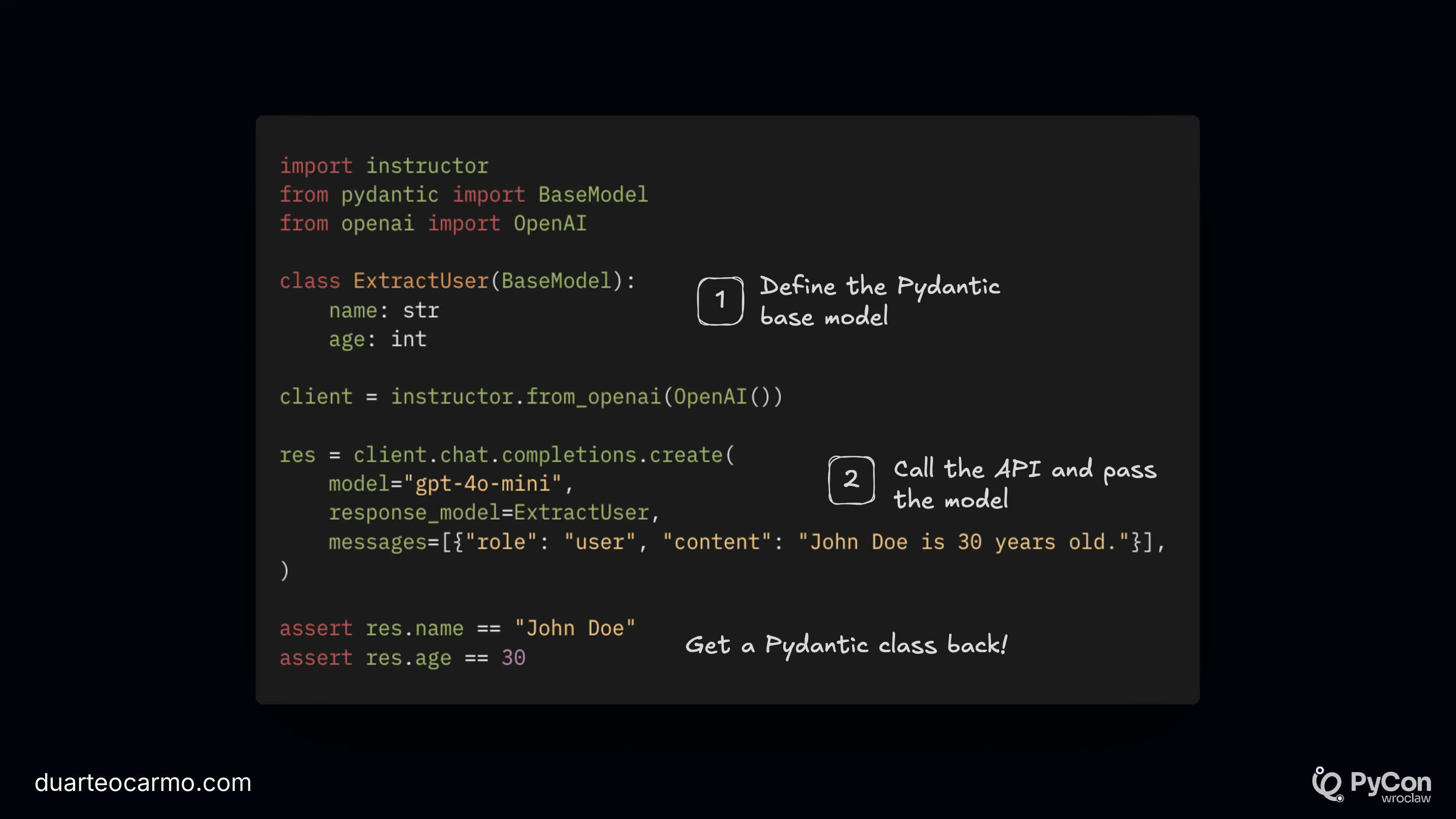
Of course, you don't need to use instructor. You can go with Structured Outputs as well.
But in general - I absolutely hate 'OpenAI code'. E.g., code that is completely locked into OpenAI or any other AI provider. So I present LiteLLM. A great tool to keep your code provider agnostic.

Here's where LiteLLM really shines. When you can switch out any model from any provider, just by switching the prompt.

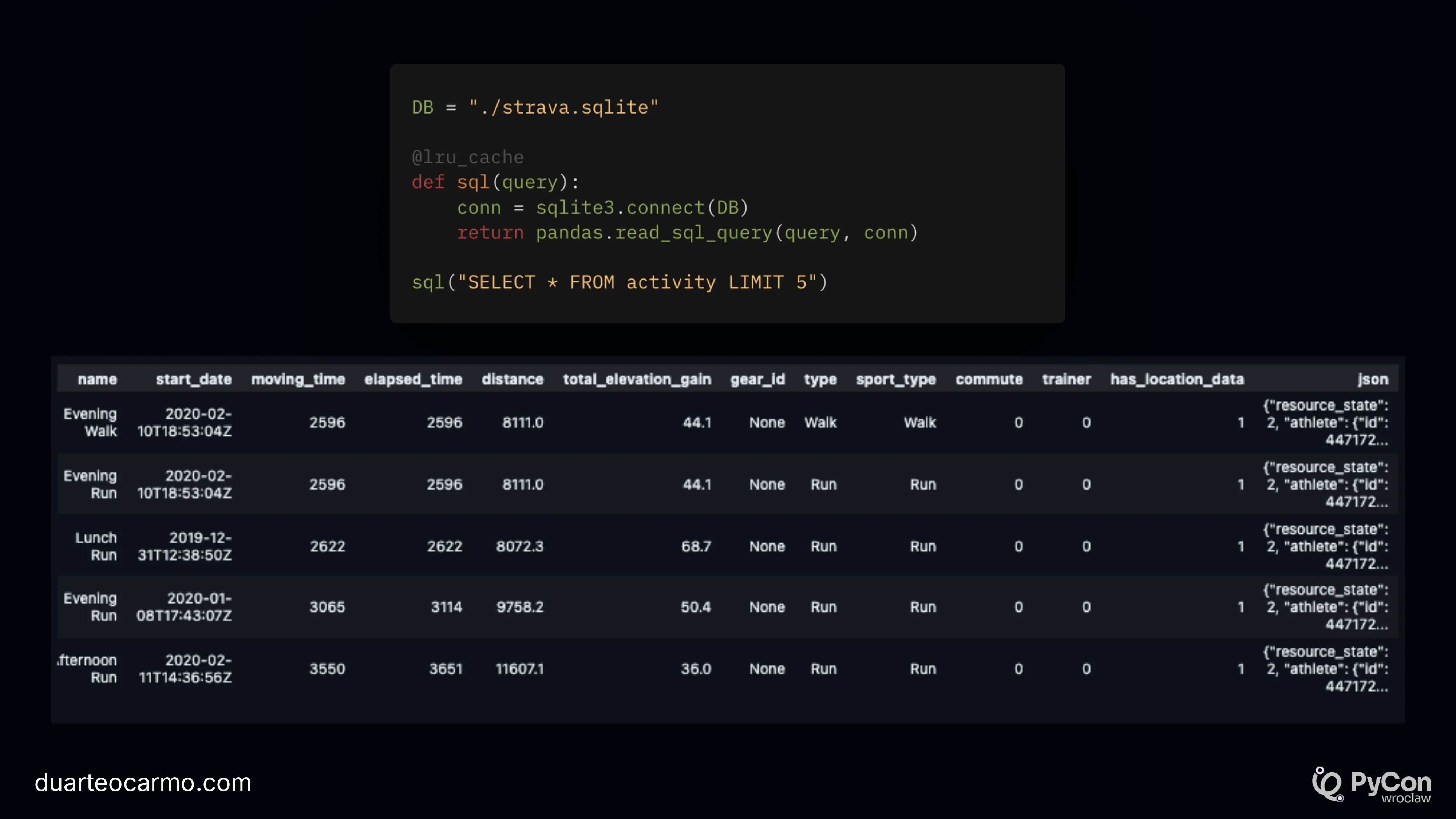
As an example I use a simple SQLite database of my running data from Strava.

Here's the code to load the Strava data and a small preview of the data.
Time to build a basic text-to-sql prompt.

My prompt structure. It includes a Preamble, the CREATE TABLE statement so that the LLM knows the structure, some response guidelines, and the user question.

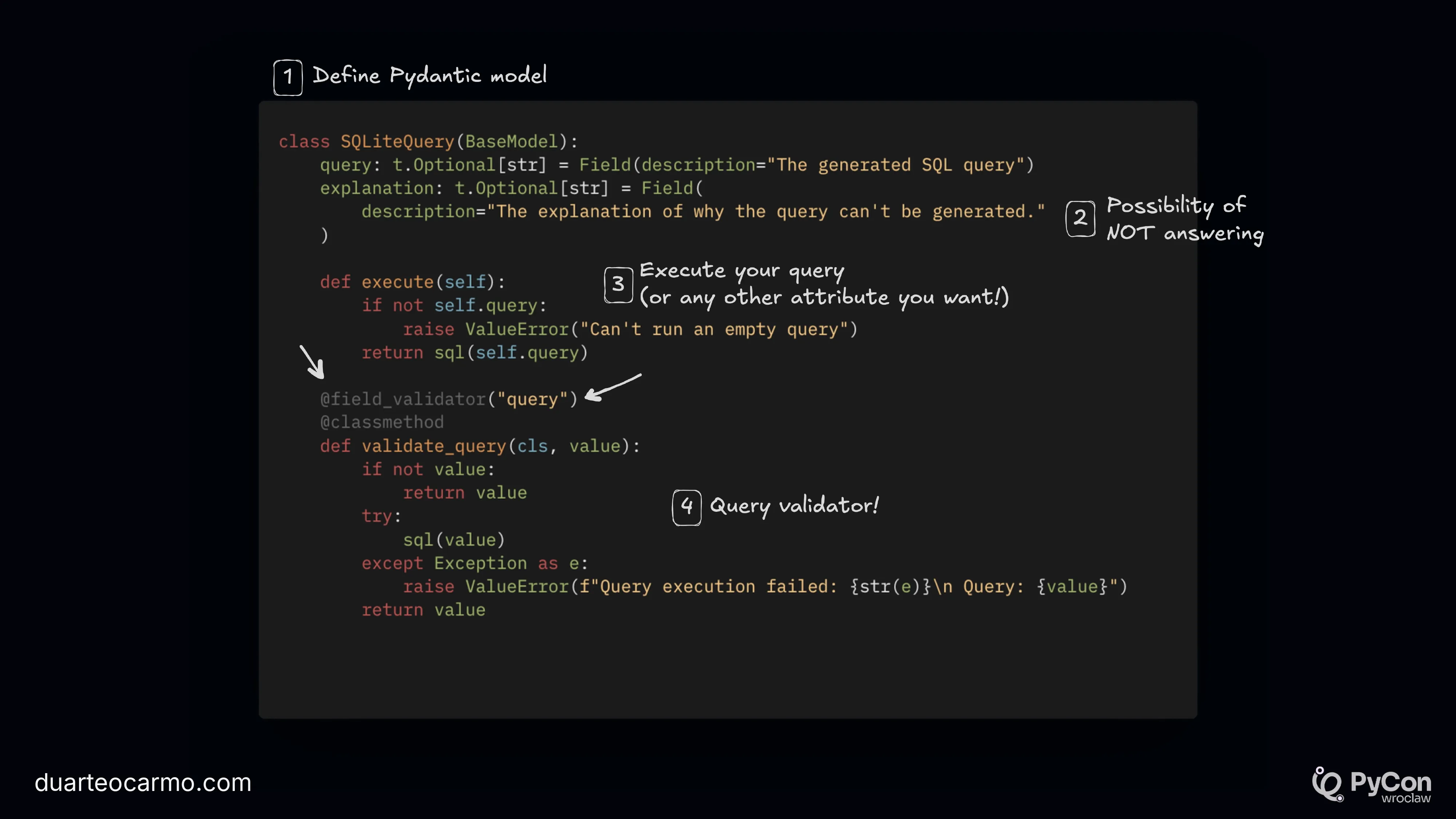
The issue with most of these systems is that we have no way to ensure a certain query is actually valid..

Here's a particularly nasty piece of code. I use Instructor to generate the SQL from a question, but also include a custom validator. This will ensure that whatever the LLM generates can actually be run against the database. This is of course, very dangerous. So one should not put this code in production, since you'll be opening yourself to all sorts of problems. But it's a nice way to ensure validity.
Here's the Frankenstein class:
And the function we use to call it.
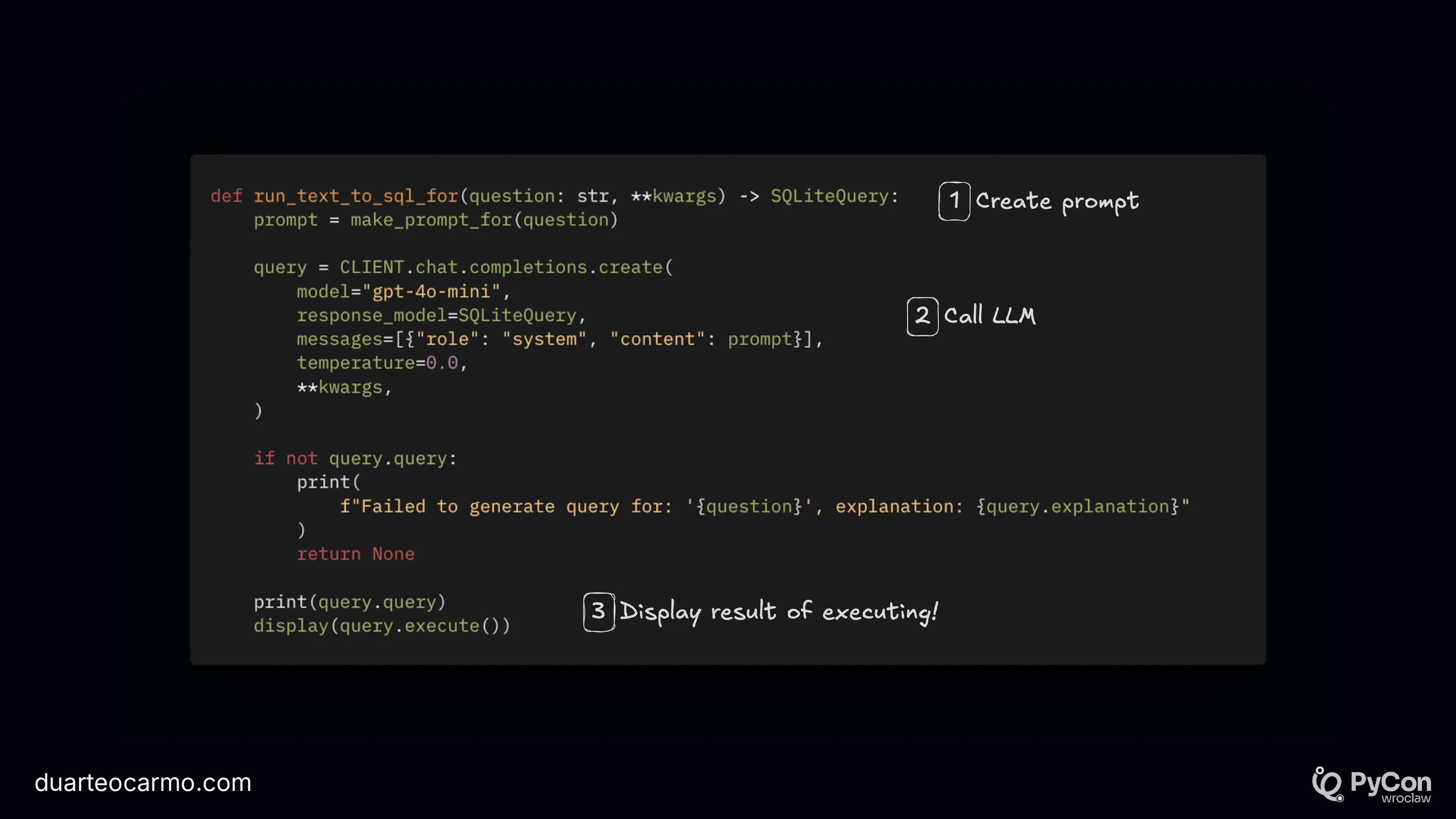
Here are some examples of running this system. With two questions. For one, it responds well. For the other, it completely fails the answer. But both answers are smooth and valid from the SQL perspective. But that doesn't mean they are correct.
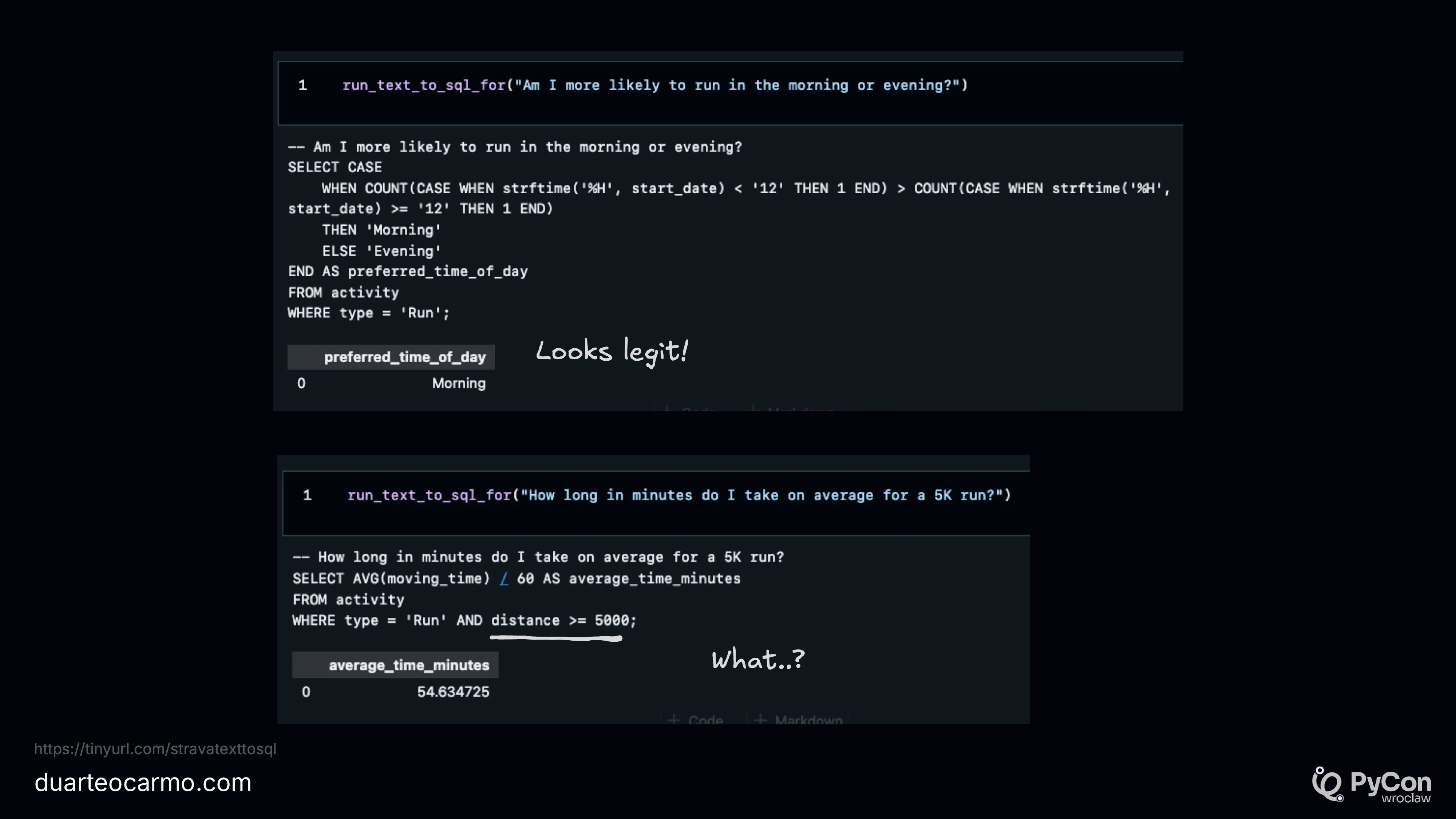
So now that we are getting valid answers, how can we ensure that they are actually good?

Once we've started with a baseline. I take Chapter 5 to talk about how to make things better once you have this baseline done.

Mandatory meme about testing and performance. If you never test, your tests never fail. If you never evaluate, your LLM system is perfect.

To improve your text-to-sql system, you actually need to measure it.

This is just like traditional Machine Learning. We can go back to one of the most well-known metrics: Accuracy.

To measure accuracy, we can create some questions based on the data from our Database. Use our LLM system to respond to those same questions, and compare both answers. That's it!
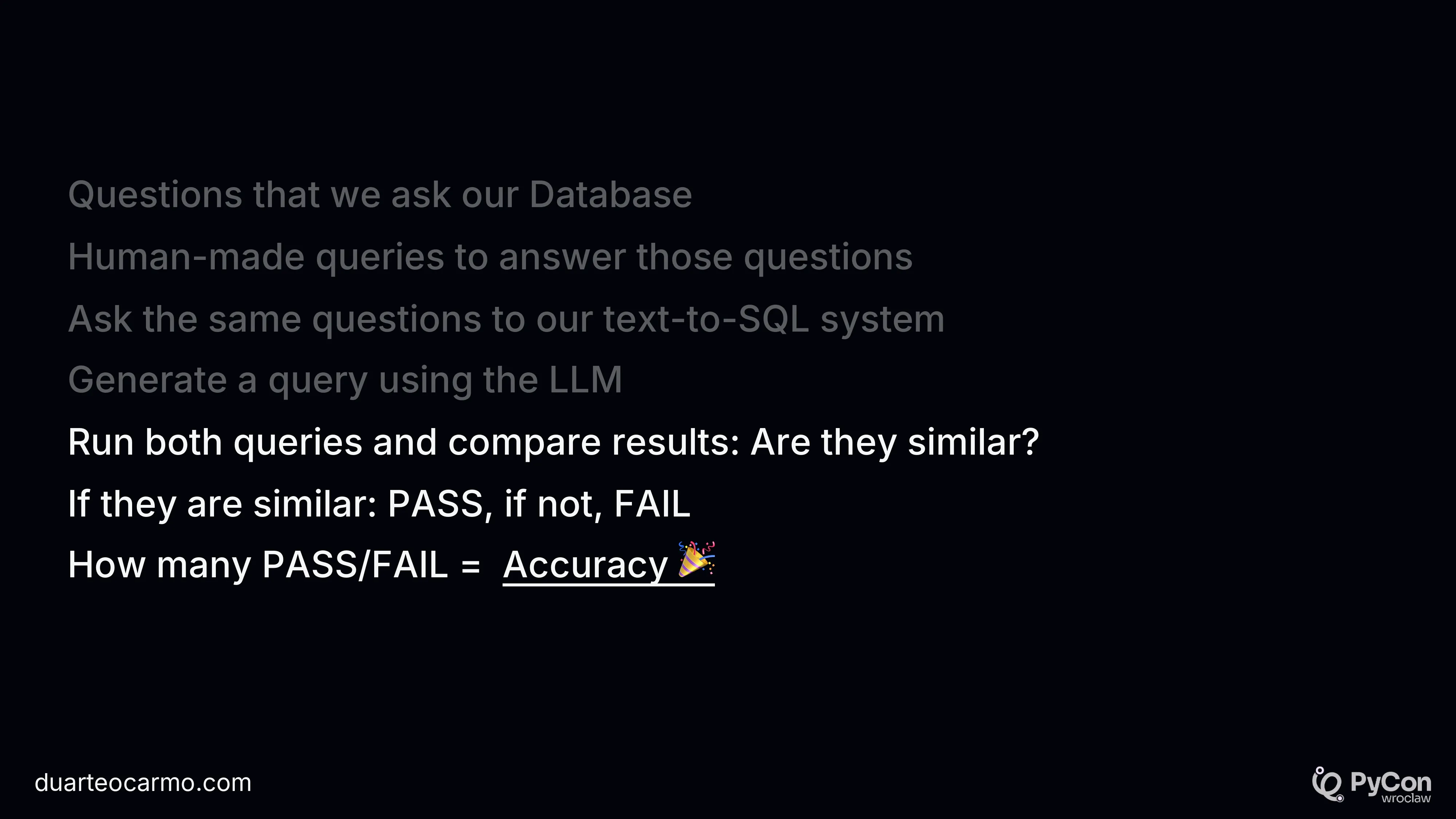
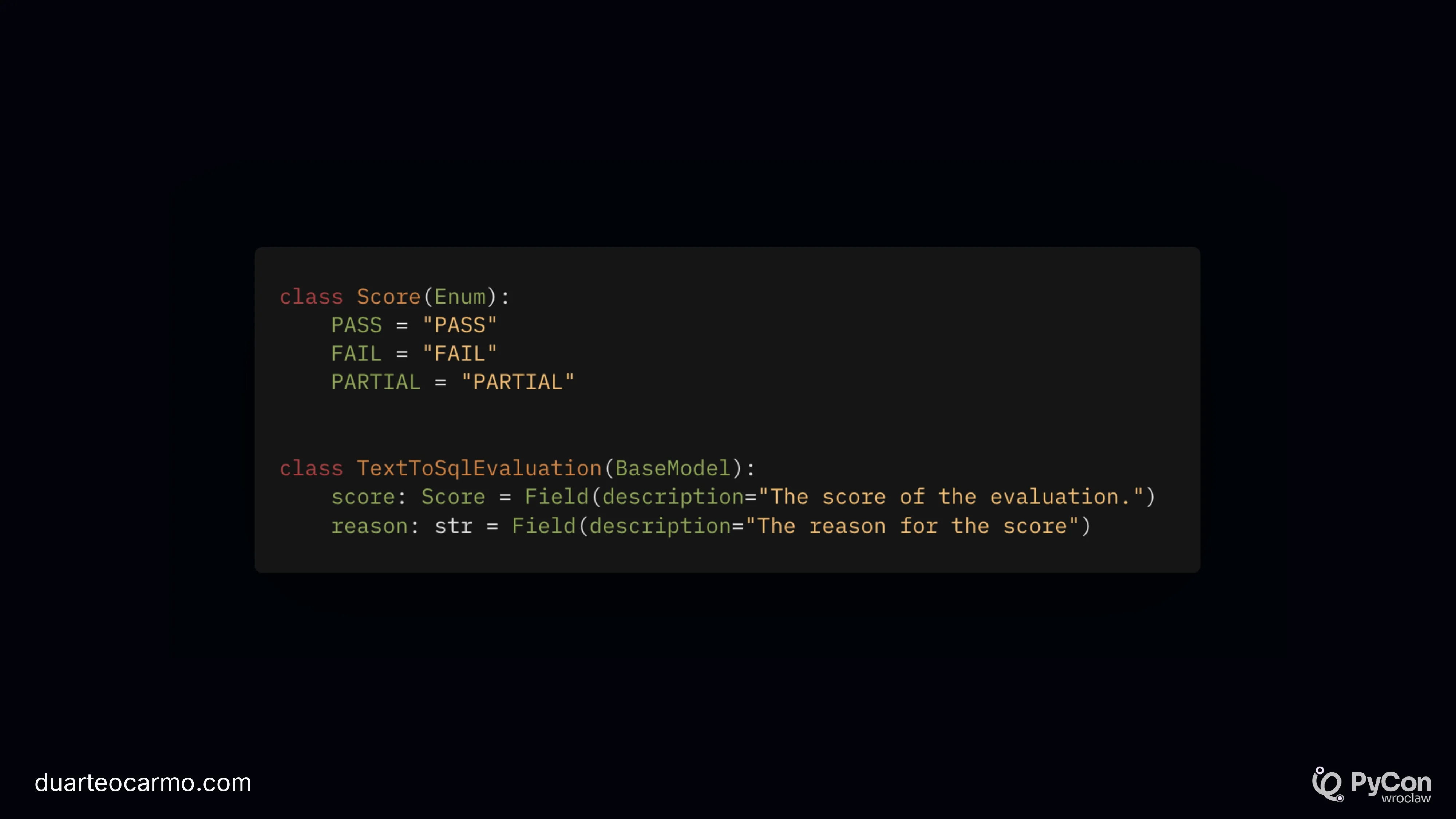
We can use instructor/structured outputs again here, to understand if our LLM answer matches the information in our baseline answer.
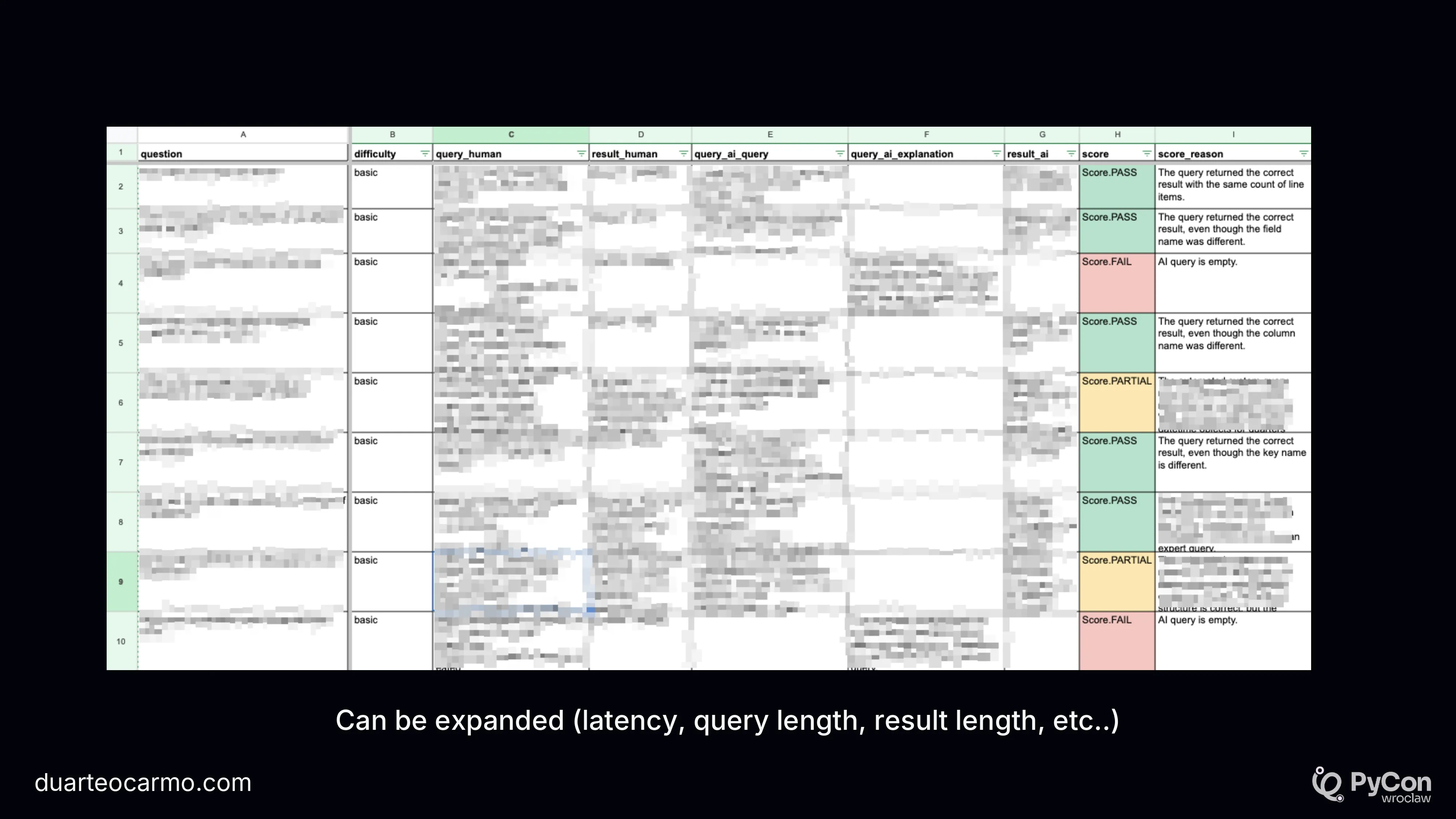
I really like looking at data, and evaluating where things go wrong. But I'm skeptical of the myriad of tools coming out to evaluate LLMs. And I'm a big fan of Google Sheets. Mainly because when I look at the data, I probably also look at it with some sort of subject matter expert. So the fewer 'things' between us and the data, the better. And Google Sheets are fine.

Here's an example of how I use Google Sheets to look at the performance of this text-to-sql system. You can see the question we want answered. The SQL and answer from our ground truth, the SQL and answer from the LLM system, and its evaluation. We also include a reason why a certain case was FAIL/PARTIAL.
This is all nice and dandy. But we should never forget the big picture. So what?

In the final slide, I come back to the three most important lessons: Iterate quickly, make the SQL generation robust and explainable, and iterate from a baseline.

I then took some questions and wrapped things up!