The largest open pretraining dataset for European Portuguese
A couple of months ago I released Bagaço - a pretraining dataset for European Portuguese. The idea was simple: take the FineWeb 2 dataset, limit it to web pages that look like they came from Portugal, and classify them into categories (Sports, Culture, etc.) and an educational score.
Pulling the European Portuguese from the wider corpus was a bit of a frustrating experience. It's a bit like finding a needle in the haystack. I avoided the problem, and just included anything with a .pt domain in the URL. But that didn't feel like it was enough.
Which led me to the next phase: European Portuguese variety identification. Or – in other words – spotting European Portuguese in the wild. After learning some bitter lessons, I built two FastText-based classifiers that achieved SOTA performance, but with 10x the throughput. So that I could run the classifier at scale.
With those two pieces in place, maybe you guessed where this was going: Bagaço v2.
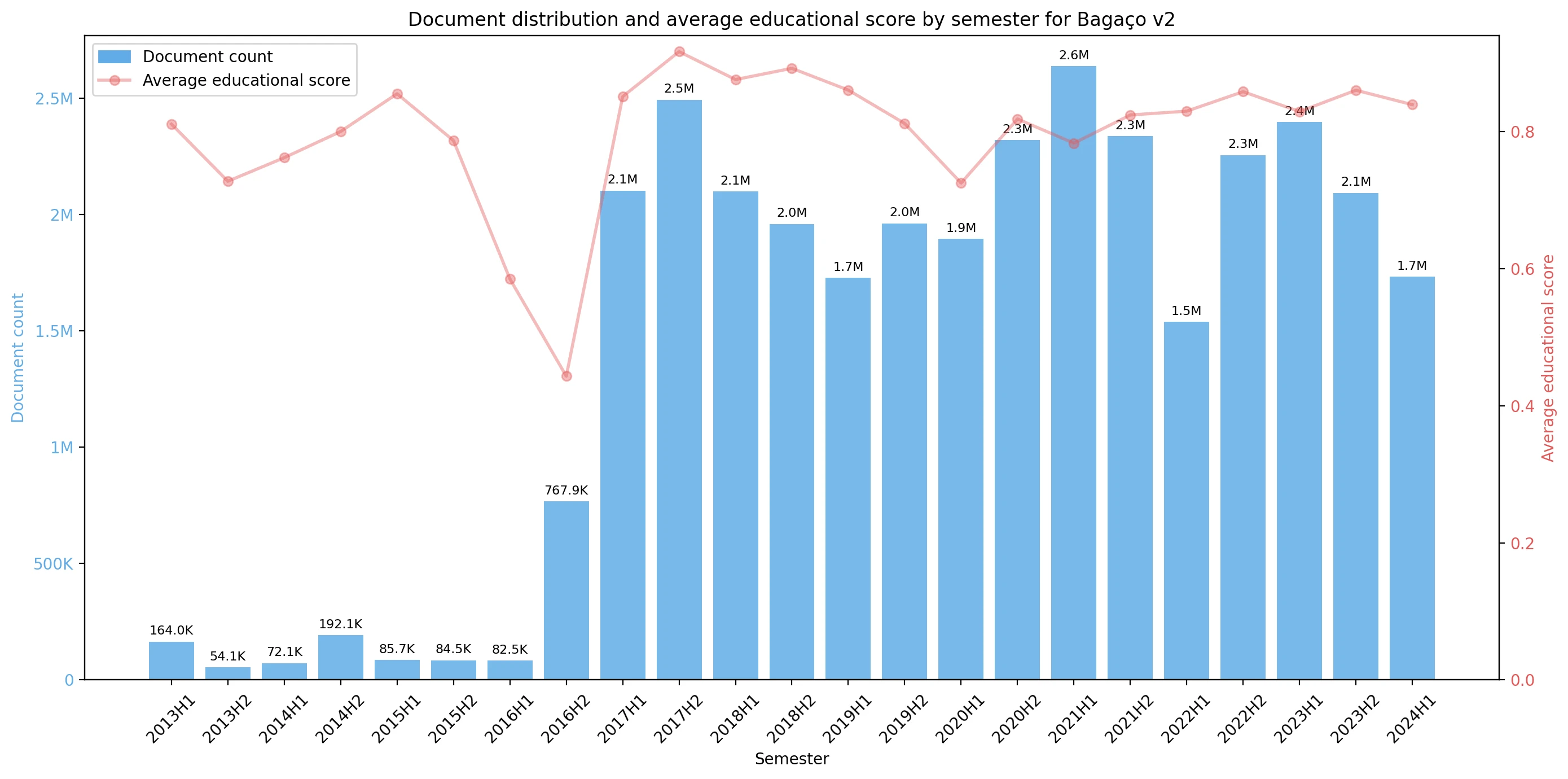
Bagaço v2 is – to my knowledge – the largest open-source pretraining dataset for European Portuguese. 33M documents, 37GB of text, approximately 9.3 billion tokens.
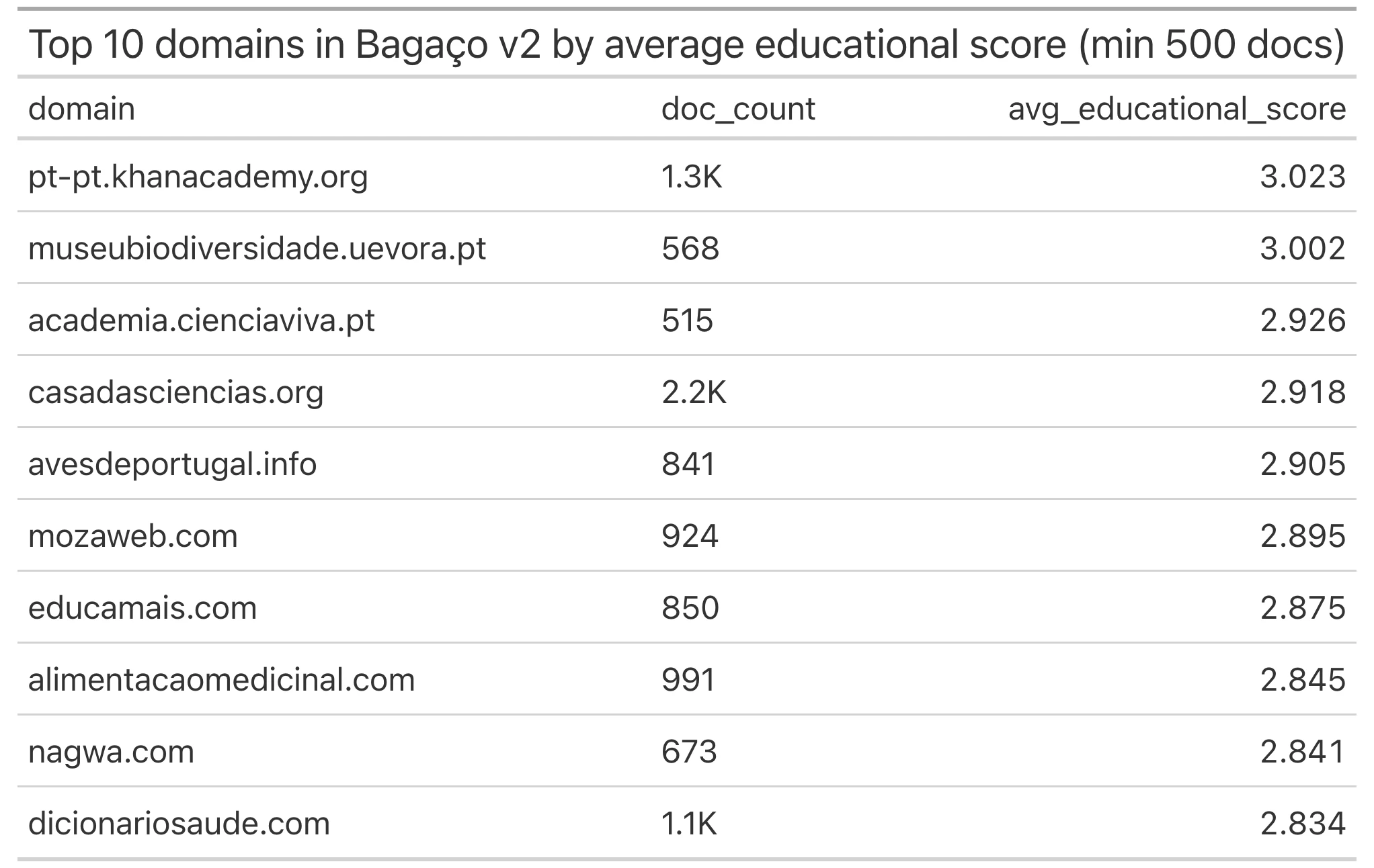
It takes the Portuguese split from CulturaX, and uses the classifier I built to only keep the European Portuguese documents (with confidence above 70%) – like before – it also gives each document an educational score and content category.
The dataset is available here.
I recently wrote about AMÁLIA and the future of European Portuguese LLMs. This most recent effort used Arquivo.pt as a data source, and collected 5.8B tokens. Bagaço v2 almost doubles that amount — and is completely open-source. One of the main conclusions of the article is that to build a strong European Portuguese LLM, we need the right data.
My hope is that Bagaço v2 takes us one step closer.