Bagaço: A pretraining dataset for European Portuguese
Let's say your goal is to train a Large Language Model only on European Portuguese. Where do you start? What datasets are out there? What websites are being scraped for the large black box? Bagaço - named after the popular Portuguese moonshine - is a small step in that direction.
In June '25, the Hugging Face team released FineWeb2. FineWeb2 succeeded FineWeb, a massive cleaned up dataset of the entire internet. Think millions of web pages, specifically gathered to train Large Language Models. FineWeb2 expanded FineWeb, by adding documents in hundreds of other languages. 199 million of those are in Portuguese, but how many of them are really from Portugal, or written in European Portuguese? That's how Bagaço was born.
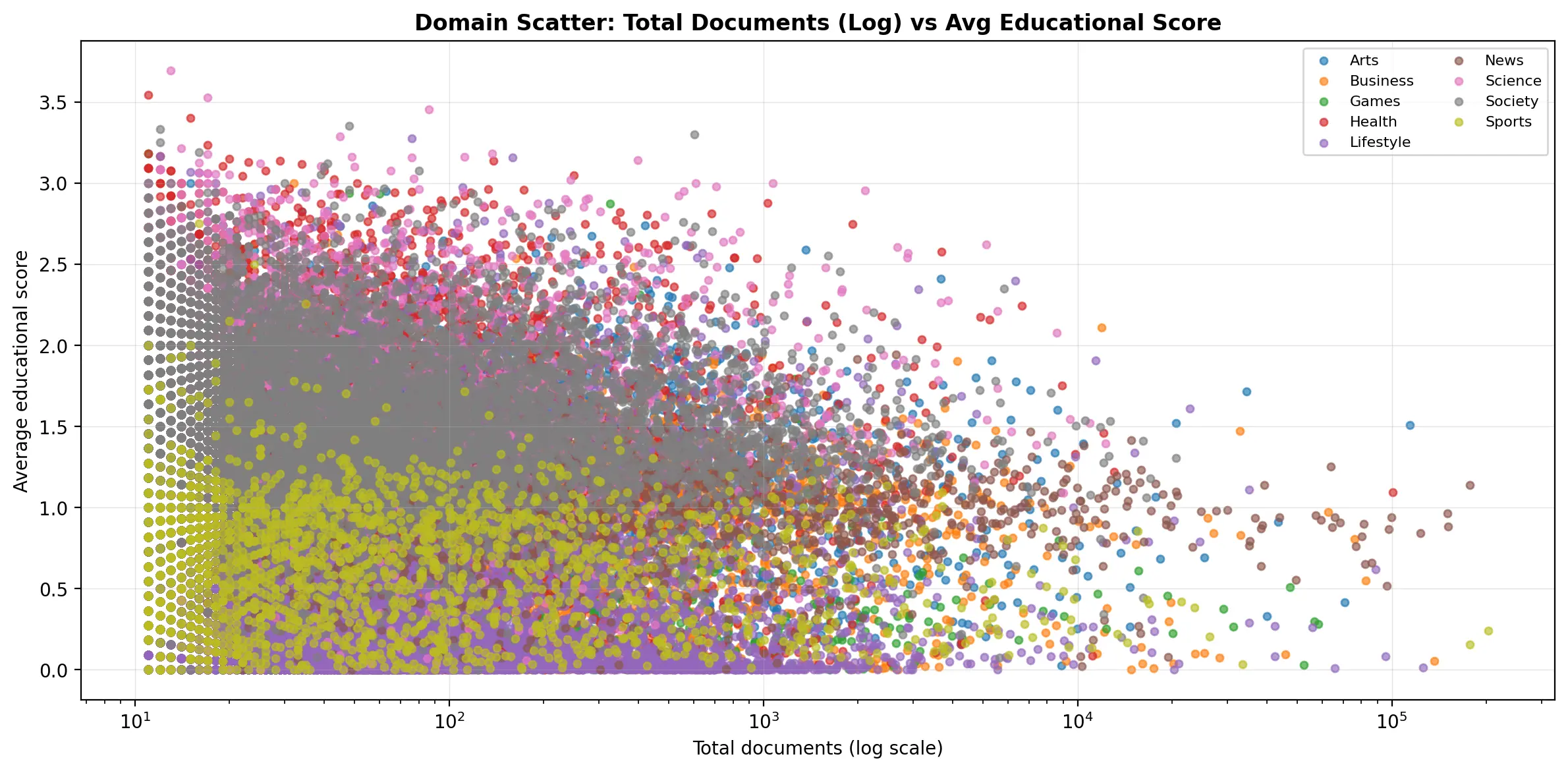
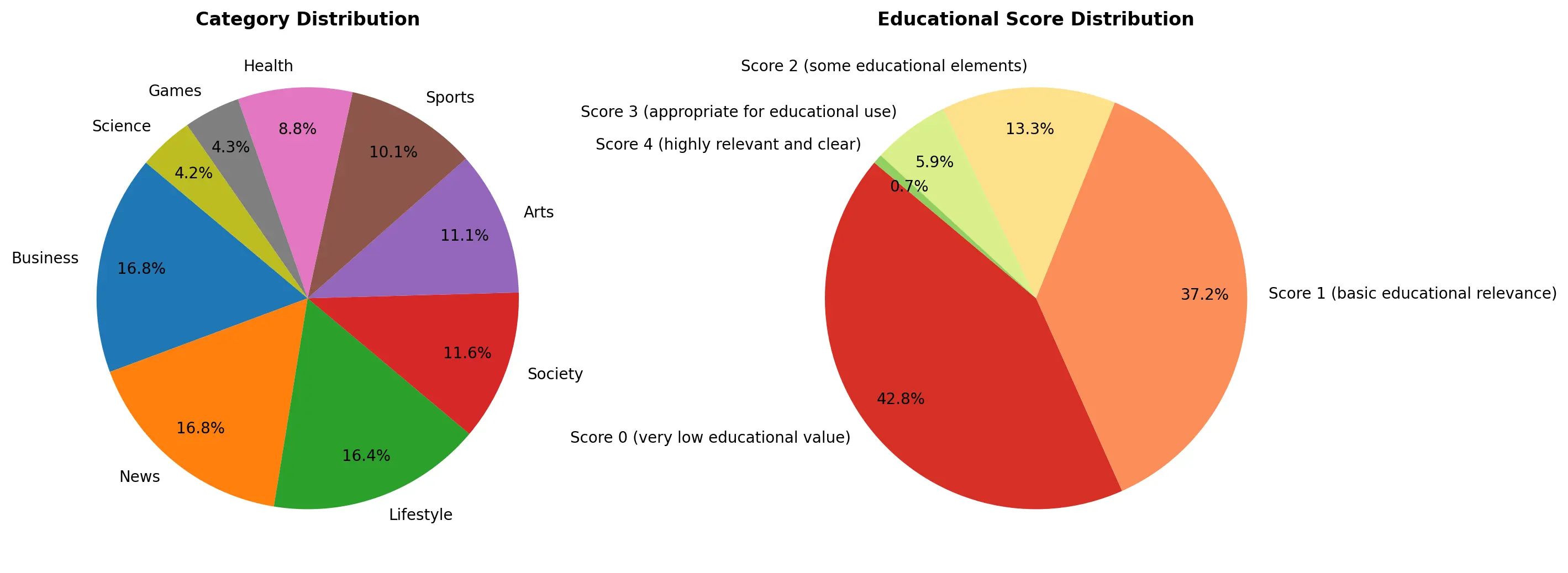
Bagaço keeps only the 16 million documents that match domains from Portugal (e.g., .pt). But it doesn't stop there. The goal of Bagaço is also to tell us a bit more about the data. I built two classifiers: the first classifies every document into one of nine categories: Society, Arts, Business, Science, Sports, Lifestyle, Health, Games, News. The second attributes an educational score to each document (from 0 to 5) this gives an educational "value" to each web page. Very inspired by the FineWeb-Edu work from the HF team. These were trained in a similar fashion: an LLM to annotate a large sample (with Gemini and Qwen), and a balanced Logistic Regression applied on e5 embeddings (more info on those here).
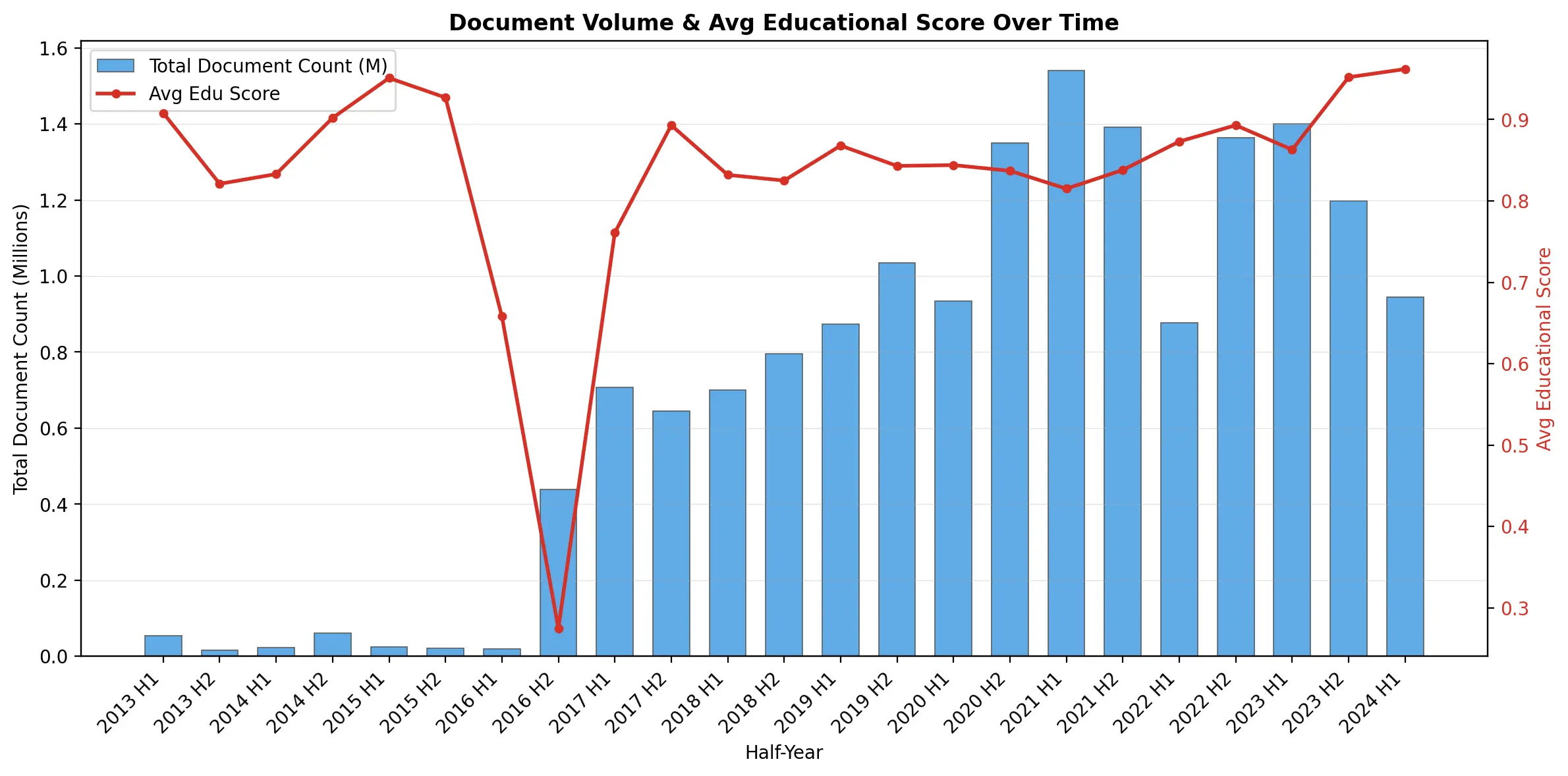
It's an interesting subset to analyze. The two most popular domains are desporto.sapo.pt and record.pt: sports news websites (I don't think I expected anything different from Portugal). The dataset is nicely distributed across categories, but something's a bit rotten. The average educational score of the dataset is only 0.85 out of 5 (!).
With FineWeb-Edu, the Hugging Face team showed that if they filtered a dataset for educational scores above 3.0, the downstream LLMs had dramatically better performance. Well, if we filter Bagaço by the same criteria, I don't think we would have much left (around 1M documents, that's it). If you're interested in more stats and facts, here's a Marimo notebook with an analysis. (Here are several scripts to create the dataset, train/run the classifiers, or to make Bagaço into an easily queryable DuckDB database)
What if we just ignored the fact that the educational score for Bagaço is pretty low and pretrained an LLM on it? (For the record, I did - it wasn't good). Bagaço has something like ~7 Billion words, something like ~9 Billion tokens of text. According to Chinchilla (~20 tokens per parameter), we could train an LLM of ~450 million parameters. Not an Opus competitor by any means - could still be an interesting model.
You see, there's still much to do in this space. Most high quality data ablations have been focused on the English language. And sure – there's a lot of English out there – but there's surely a lot of European Portuguese data out there too! We just have to find it! We probably can't get away with just filtering a dataset by .pt domains. We might need something more sophisticated. But data is not the only bottleneck, we also need better evaluations for European Portuguese.
Bagaço is only the first try. The potential is huge! Time to get to work.