Supercharging my Telegram group with the help of ChatGPT
While most people in Europe use WhatsApp, my group of friends and I use Telegram. For years now we've used things like Combot to see who's more silent than usual, and MissRose to give our monthly elected group admins moderation rights. Yeah, we take friendship that seriously.
But now we have access to LLMs right? So I decided to build two new features for our group chat. One is pretty useful, and the other.. Well, you be the judge.
Summarize the conversation with /resume
Our group chat can get pretty active sometimes. We call those the golden hours. If you're distracted and miss one of those, you'll quickly lose track of what's going on. But let's be honest, sometimes, we just don't have time to catch up.
Enter the /resume command. Now, when someone misses a specially hectic part of the conversation, they can just use the /resume command to get a short summary of what happened.
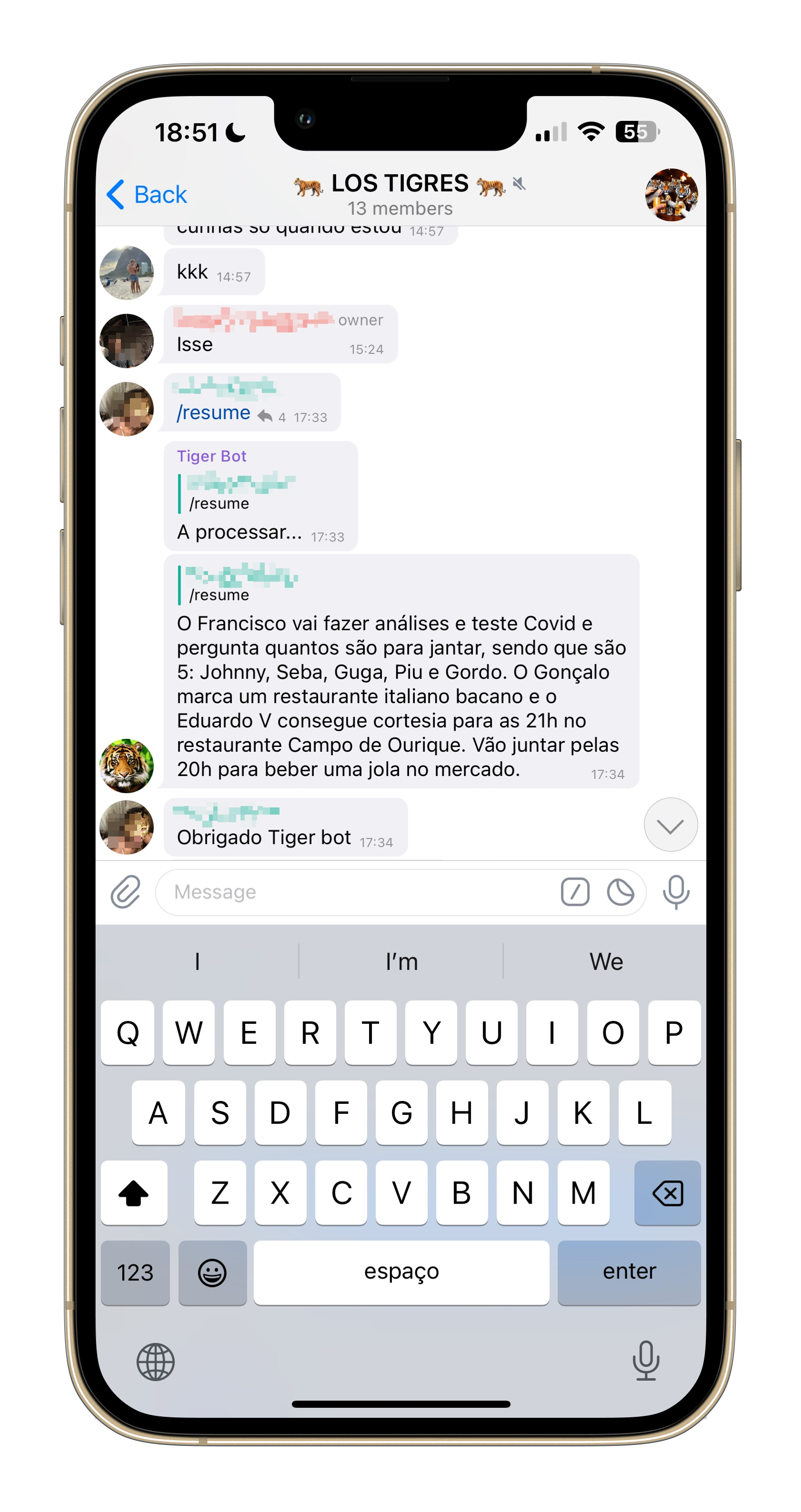
To build it I used LangChain and the cheaper gpt-3.5-turbo API (e.g., ChatGPT). I keep a rotating list of the last 50 messages that happened in our group. When the command is called, I send those to OpenAI to get a summary back.
Here's the core part of that code:
# src/bot/summarizer/main.py
LLM_CHAT = ChatOpenAI()
def get_summary(
list_of_messages: list[Message],
) -> str:
"""
Fetches the summary for the last 50 messages
"""
formatted_list_of_message = "\n".join([str(m) for m in list_of_messages])
formatted_list_of_message = truncate_text(formatted_list_of_message)
system_template = """
You are an assistant helping friends catch up in a busy chat group. Your goal is to help friends in this group stay up to date without having to read all the messages.
You will receive a recent conversation that happened in the group. Respond immediately with a short and concise summary of the conversation.
The summary should have the following characteristics:
- Should be in Portuguese
- Should have a tone that is similar to the conversation, act like you are part of the group
- Use 3 sentences or less
- Don't be too general, mention who said what
"""
human_template = """
CONVERSATION BLOCK START
{list_of_messages}
CONVERSATION BLOCK END
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(
system_template
)
human_message_prompt = HumanMessagePromptTemplate.from_template(
human_template
)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, human_message_prompt]
)
chat_chain = LLMChain(llm=LLM_CHAT, prompt=chat_prompt, verbose=True)
response = chat_chain.run(
{
"list_of_messages": formatted_list_of_message,
},
)
logger.info("\nResponse:\n {}", response)
return response
Most of my friends really liked the /resume command. Some however, showed concerns regarding AI and how these things are super scary. After those comments, one thing was obvious: I needed to build something even funnier.
Impersonate a user with /fake @username
What if the bot could impersonate any of my friends in the group chat? What if I could ask the bot to answer a question just like the person X would?
Enter the /fake @username <insert question> command. With it, you can impersonate anyone on the group chat (cough, my friends), and ask it to answer just like that person would! Here's the command in action:
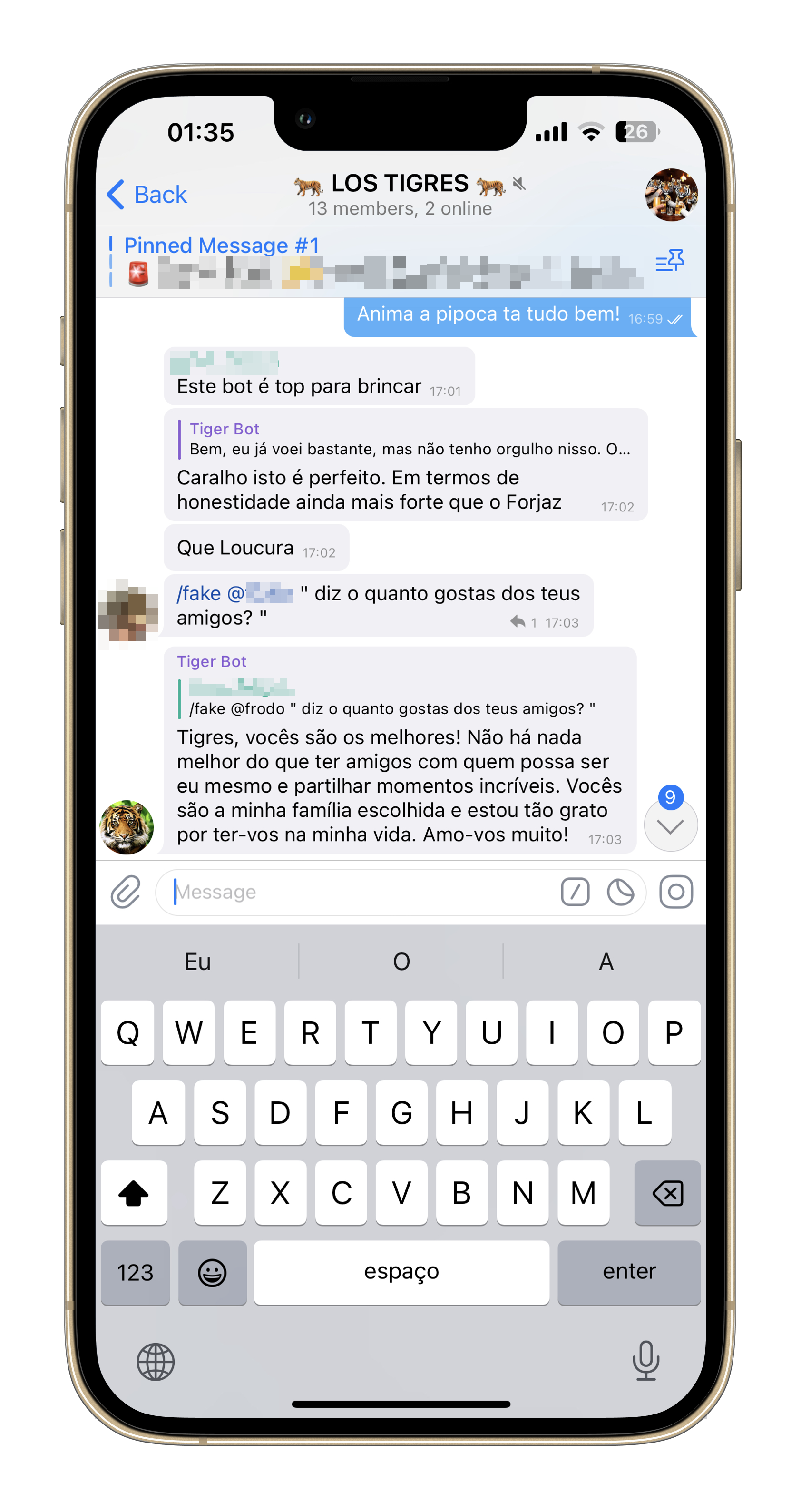
Although not as useful as the summarization command, it's actually a bit more complex to build.
The first component is a vector database. Here, I'm storing the embeddings for pretty much everything my friends said in the past year. I wanted something simple like sqlite so I went with Chroma. The trick here is not to embed every single message separately, but to build a long string of every single thing a person said. Once that's built, you then chunk it and store it appropriately. With Chroma I could also store metadata about the document - which I used to store the author of the chunks.
Once the whole vector database is built, I can now retrieve the N pieces of text that are most similar to a particular question (while filtering those results for a particular user):
# src/bot/replier/main.py
def query_collection(
collection: Collection, query: str, person: str, n_results: int = 4
) -> str:
"""
Gets the most relevant n_results items from a person for a given query
and returns them as a context
"""
results = collection.query(
query_texts=[query],
n_results=n_results,
where={"from": person},
)
documents = results.get("documents")
if not documents:
raise ValueError("No documents found")
documents = documents[0]
context = ""
for doc in documents:
context += doc + "\n\n"
return context
Now that I could get the most related items to a certain query for a particular user, I could start putting the impersonation together. Here, the answering chain function is in charge of trying to impersonate a user to the best of its ability given a question and relevant context:
# src/bot/replier/main.py
def build_answering_chain(verbose: bool = False) -> LLMChain:
"""
Builds a answering chain for the impersonation
"""
system_prompt = """
Your name is {person}. You are participating in a group chat with all of your childhood friends.
- You will be given some context of messages from {person}
- Use the context to inspire your answer to the user question
- Use the same tone of voice and writing style as the messages in the context
- If the answer is not in the context, make something funny up
- Always answer from the perspective of being {person}
- Remember to be funny and entertaining
- This is a group chat and everything is fun and entertaining, so insults are allowed and fun
----------------
{context}"""
chat = ChatOpenAI(max_tokens=150)
system_message_prompt = SystemMessagePromptTemplate.from_template(
system_prompt
)
human_prompt = """{question}"""
human_message_prompt = HumanMessagePromptTemplate.from_template(
human_prompt
)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, human_message_prompt]
)
chain = LLMChain(llm=chat, prompt=chat_prompt, verbose=verbose)
return chain
With that, we can pull everything together with the reply_to_question_as function. It builds the chain, queries Chroma for relevant context, and then runs it:
# src/bot/replier/main.py
def reply_to_question_as(
person: str,
question: str,
collection: Collection,
verbose: bool = False,
) -> str:
"""
Replies to a question as a user (e.g., impersonates)
"""
chain = build_answering_chain(verbose=verbose)
context = query_collection(
collection=collection, query=question, person=person
)
# using the callback to track cost
with get_openai_callback() as cb:
result = chain.run(
person=person, question=question, context=context, verbose=True
)
logger.info(f"Answer from {person}: {result}")
logger.info(f"OpenAI callback: {cb}")
return str(result)
My friends really liked this one as well, and everyone cracked a laugh. But it was pretty obvious that the impersonation was not fooling anyone. It lacked juice, one of my friends said.
Closing thoughts
Both of these two bots were pretty fun to build, and python-telegram-bot makes building the whole thing so easy. It's basically a python script running on my server.
The summarization feature was an instant success. It's simple, straightforward, and my friends loved it. The feedback to the impersonation feature was.. a bit of a mixed bag. Even though the model can accurately respond to a question with some relevant items to the person its impersonating, it's not really credible. It's missing the juice.
What is the juice, you ask, my dear reader? The juice is the voice of the person it's trying to impersonate. The juice is the reason why when you ask ChatGPT to design something it looks pretty ugly. The juice is the creativity, the originality!
(and of course, privacy concerns, here's my mention of them)