Self-hosting my personal LLM (but not quite)
ChatGPT is now part of our daily lives. A quick question, an extra input, some quick feedback, I always reach for it. AGI or not AGI, I certainly can't deny the impact it has had on our lives. It's pretty incredible!
But that small voice just won't go away. "Where is all this data going? Should I really be telling this bot this much? What if someone else sees this?" In a way, it feels like everything I tell this bot is going into a void I have no control of. I can't be the only one feeling it.
And I don't like it. It's a bit like putting all my eggs in a single basket. As engineers, we know how bad having a single point of failure is. Resilience! That's what we were taught.
Given that I already started building Ambrosio, so why not use it to self-host my own LLM?
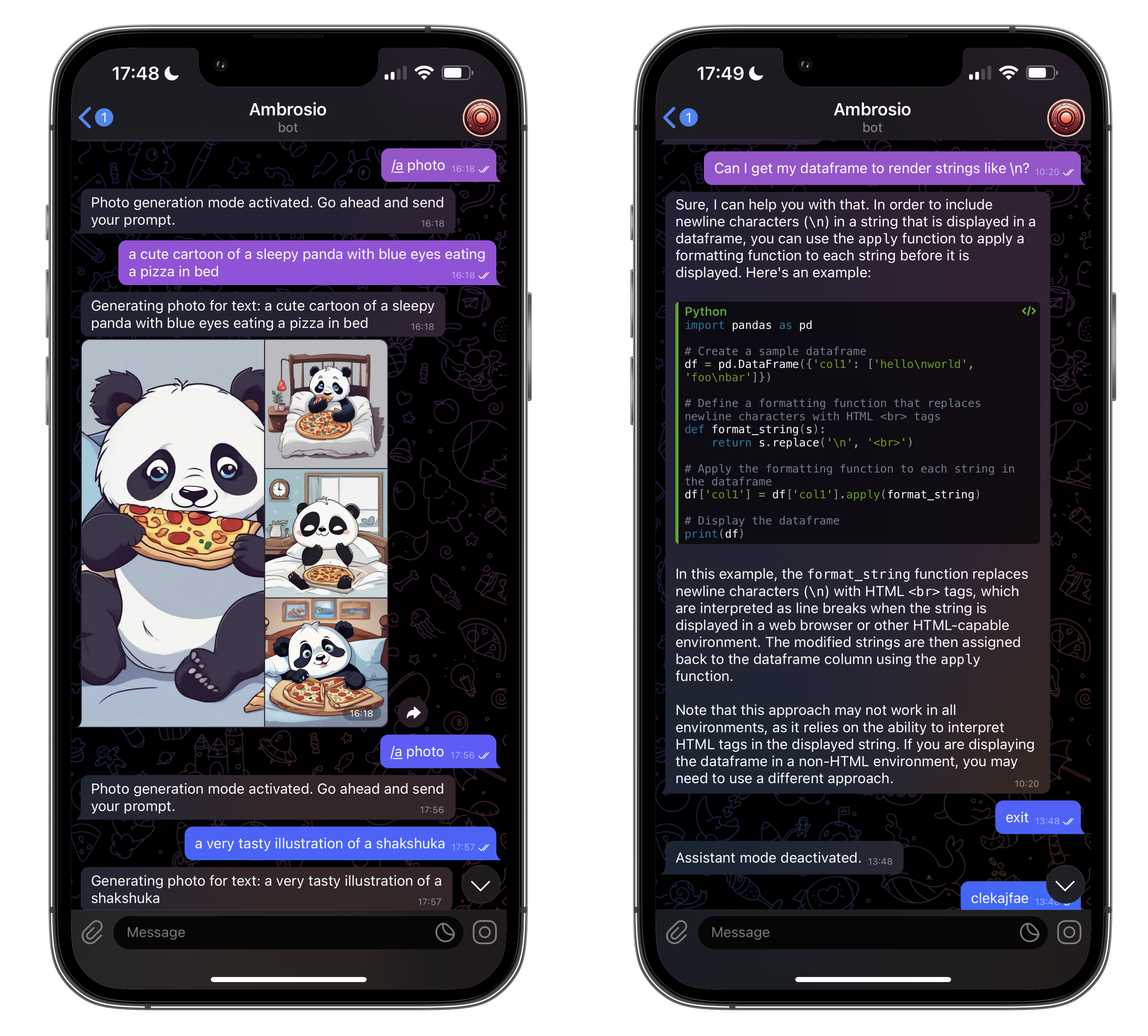
Self-hosting with the help of Llama.cpp
I'm not really interested in spending 500 USD/month to run a model that requires 40 GB of VRAM on a large GPU. So I had to lower my standards a little bit. The premise was now: What models can I run on a 15 USD/month server?
I started looking at the only LLM leaderboard I trust. There aren't many options with 7 billion parameters. The best one seems to be Starling-LM-7B-alpha, out of Berkeley. Quantized, it should just about run on a cheap Hetzner box. Getting it up and running on a small box with llama.cpp is as easy as:
# download model
$ wget https://huggingface.co/TheBloke/Starling-LM-7B-alpha-GGUF/resolve/main/starling-lm-7b-alpha.Q5_K_M.gguf?download=true
# setup llama cpp API with ./server
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp
$ make
$ ./server -m starling-lm-7b-alpha.Q5_K_M.gguf -c 8192 --temp 0.0 --repeat_penalty 1.1 -n -1 -p "GPT4 User: {prompt}<|end_of_turn|>GPT4 Assistant:"
And just like that, you're running your own OpenAI compatible (ugh, I hate that term) API serving that very 7B model.
Now, don't get me wrong, I think this model is great! But I'm looking for something that will replace my daily use of ChatGPT. After integrating with Ambrosio the limitations were obvious. The first issue: It's slow, painfully slow (which was expected on my small machine). And even though it's pretty incredible for a small model, it's not going to replace even the most basic use cases.
And if it sounds unfair in any way, it's because it is! How could I expect the same level of quality from something that can run on a cheap VM, to something like ChatGPT? And you're right. We can't. So what else can we do?
Mixtral 8x7B and the rice test
Let's say I was going to rent a bigger machine for a better model. What would I run on it? Certainly not a 7B model! Looking at the rankings again, the best open source thing currently is Mixtral 8x7b, a mixture-of-experts model from Mistral. Just glancing at the requirements, and it was pretty clear this needed to be run on someone else's box. I decided to give together.ai a go. Their pricing is pretty much unbeatable and their inference speed is blazingly fast. And of course they have an Open AI compatible API.
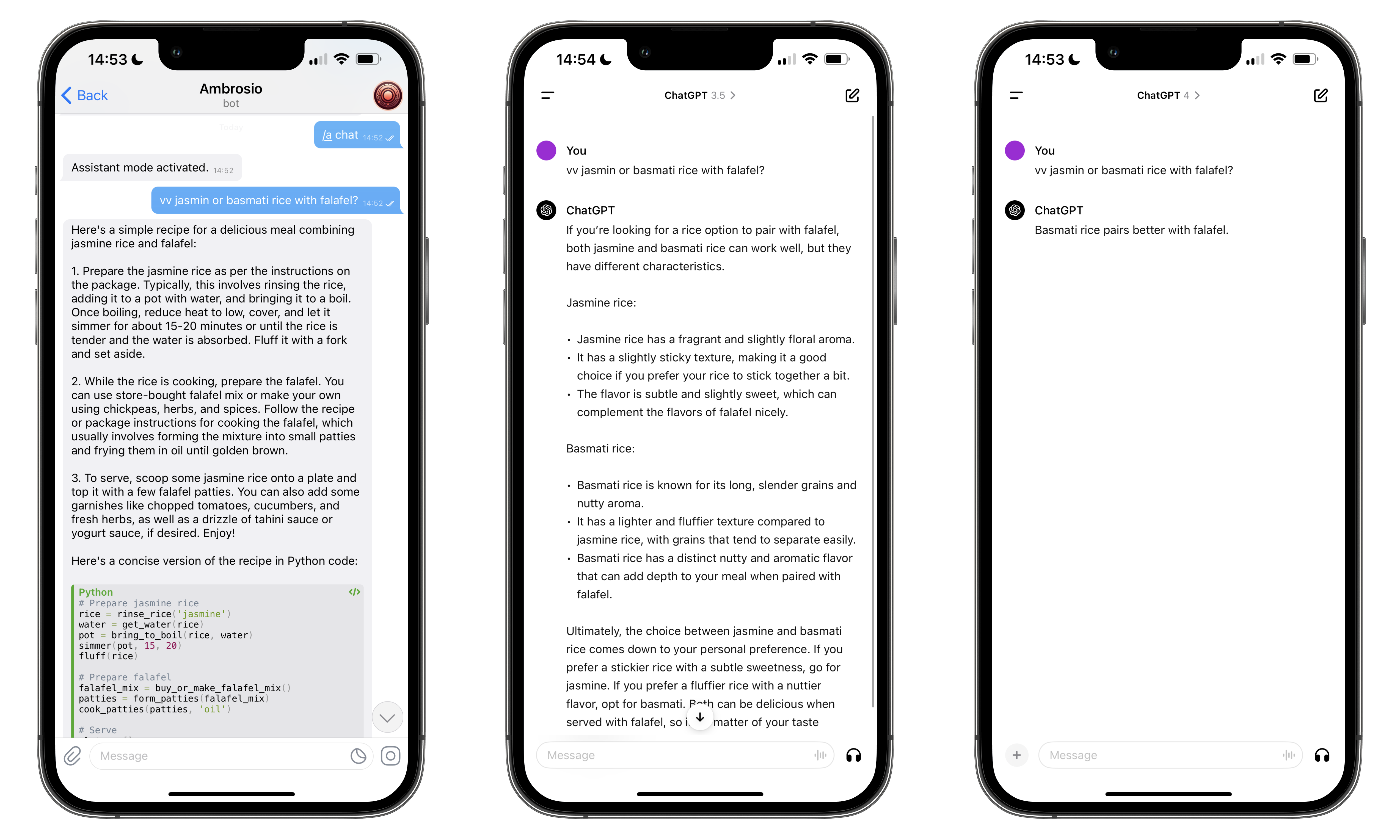
Cool, it's fast and cheap. Is it any good?
Everyone has their own way of testing the quality of a model. Mine is what I call the "rice test". My system prompt, stolen from Jeremy Howard contains the following clause:
if the request begins with the string "vv" [...] make your response as concise as possible
The question above is a simple and straightforward scenario. I'm at the supermarket, I need to buy some rice to cook with my falafel. I open my phone and: "vv jasmin or basmati rice with falafel?". As you can see above, while GPT-4 gives me exactly what I need, we can't say the same for Mixtral or GPT-3.5. I just want a quick and dirty answer, I don't want something complicated, I certainly do not want any Python code. So yeah, it doesn't quite pass the jasmin rice test. But we're getting closer. And I will keep testing it in the future.
And sure, Mixtral may not have been trained with a system prompt, but it should, in principle, support it.
Thoughts and taking Ambrosio further
Since I ended up using together's API, I decided to also add image generation to Ambrosio (something like I have with DALL·E 2). Together supports most Stable Diffusion models. My feelings about them are largely the same as my feelings about Mixtral and GPT-4. The open source models are good! But they are also a bit rough, and don't come quite close to what Open AI is giving us. At least yet.
So, will Ambrosio completely replace my use of GPT-4? Will I cancel my ChatGPT plus subscription? Not really. At least, not yet.
Every time I use these open source models, I feel like I'm missing out on a better answer. In a way, I've become spoiled by GPT-4. It just grasps what I want in a better way, and most importantly, it passes the rice test with flying colors!
But the truth also is, that for most tasks, Mixtral is good enough. And it's a big leap forward from what the open source community previously had. I can only imagine what comes next.
Exciting times.