RAG tricks from the trenches

Notebook download - nbsanity preview
Some context
We had a database of 50M strings and I couldn't wait to embed them all. Embeddings for recommender systems were, for a long time, the HOLY grail I longed for. I still remember, long before the RAG rage, having conversations with Pedro about the amazing types of applications we could build with embeddings.
In a way - RAG has come a long way. From another side: but RAG is still the same. It's just search! Over embeddings.
For the past 2/3 years, the number of applications doing some sort of RAG has increased significantly. I've learned a trick or two over that time.
Here are some tricks I've learned along the way in hope someone else can benefit from them as well.
Important notice: Almost none of these are mine. And that's why I like them.
# !pip install polars jupyter_black fasttext huggingface_hub lancedb litellm sklearn sentence_transformers
import polars as pl
import jupyter_black
import fasttext
from huggingface_hub import hf_hub_download
import lancedb
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
from datetime import datetime
from litellm import completion
from sklearn.cluster import KMeans
import random
import json
pl.set_random_seed(42)
jupyter_black.load()
# CONFIGURATION
EMBEDDING_MODEL = "all-MiniLM-L6-v2"
LLM = "ollama_chat/llama3.1"
TABLE_NAME = "skeets"
DEVICE = "mps"
Our data: A controversial dataset
Remember that guy that got pretty much banned from BlueSky for collecting a dataset of 1 Million skeets? Well, our dataset is a nice collection of not 1, but 2! 2 Million BlueSky posts. Isn't that controversial?
I'm really enjoying Bluesky by the way. You should follow me there in case you come across this!
Alright, let's load the dataset using Polars:
df = (
pl.scan_ndjson("hf://datasets/alpindale/two-million-bluesky-posts/*.jsonl")
.filter(pl.col("reply_to").is_null())
.collect()
)
df = df.with_columns(pl.col("created_at").cast(pl.Datetime))
df = df.with_columns(pl.col("created_at").dt.strftime("%Y-%m").alias("month_year"))
df = df.with_columns(pl.col("created_at").dt.strftime("%Y").alias("year"))
df = df.sample(50_000) # so that we run fast.
print(f"{df.shape=}")
print("Example skeets:")
df.sample(2).to_dicts()
df.shape=(50000, 8)
Example skeets:
[{'text': "The last time I was back in the U.S. to visit family for Thanksgiving was in 2008, shortly after Obama was elected. People were elated and optimistic. The future looked bright.\nToday it could hardly be darker. That's what the MAGAs have brought us: chaotic dictatorship.\nI'll stay home in Canada.",
'created_at': datetime.datetime(2024, 11, 27, 15, 30, 22, 133000),
'author': 'did:plc:cnxppns7qxo2wzdlutmxbkih',
'uri': 'at://did:plc:cnxppns7qxo2wzdlutmxbkih/app.bsky.feed.post/3lbwumhstsc2e',
'has_images': False,
'reply_to': None,
'month_year': '2024-11',
'year': '2024'},
{'text': '9 Top CSS Essential Skills That Every Web designer Should Learn – http://bit.ly/vVyTg #CSS #webdesign',
'created_at': datetime.datetime(2009, 10, 17, 17, 32, 37),
'author': 'did:plc:id2rbt2kysdnscdrzh5o5n7d',
'uri': 'at://did:plc:id2rbt2kysdnscdrzh5o5n7d/app.bsky.feed.post/3lbwmyaeat42n',
'has_images': False,
'reply_to': None,
'month_year': '2009-10',
'year': '2009'}]
Without much surprise, most of our posts (88%) are from November '24.
min_date = df["created_at"].min()
max_date = df["created_at"].max()
total_months = (max_date.year - min_date.year) * 12 + (max_date.month - min_date.month)
print(f"min_date: {min_date}, max_date: {max_date}")
print(f"total_months: {total_months}")
df.get_column("month_year").value_counts(normalize=True).sort(
"month_year", descending=True
).head(10)
min_date: 2007-10-19 21:50:33, max_date: 2024-11-28 05:08:13.636000
total_months: 205
| month_year | proportion |
|---|---|
| 2024-11 | 0.87644 |
| 2024-10 | 0.00028 |
| 2024-09 | 0.00028 |
| 2024-08 | 0.00038 |
| 2024-07 | 0.00072 |
| 2024-06 | 0.00032 |
| 2024-05 | 0.00024 |
| 2024-04 | 0.00036 |
| 2024-03 | 0.00032 |
| 2024-02 | 0.00054 |
Even though the dataset mentions to have a configuration with the language of each skeet, I didn't manage to find it.
But to keep things simple, let's use the same model they did (glotlid) and keep skeets in English only.
model_path = hf_hub_download(repo_id="cis-lmu/glotlid", filename="model.bin")
model = fasttext.load_model(model_path)
text_list = df["text"].to_list()
text_list = [t.replace("\n", " ") for t in text_list]
predictions, confidences = model.predict(text_list)
is_english = [p[0] == "__label__eng_Latn" for p in predictions]
df = df.with_columns(pl.Series(is_english, dtype=pl.UInt8).alias("is_english"))
print(f"total rows: {df.shape[0]}")
df = df.filter(pl.col("is_english") == 1)
print(f"total rows after filtering: {df.shape[0]}")
total rows: 50000
total rows after filtering: 22528
A stupid simple vector store
Lancedb provides a great interface that combines sentence-transformers + pydantic.
db = lancedb.connect("/tmp/db")
model = (
get_registry()
.get("sentence-transformers")
.create(name=EMBEDDING_MODEL, device=DEVICE)
)
class Skeet(LanceModel):
text: str = model.SourceField()
vector: Vector(model.ndims()) = model.VectorField()
author: str
created_at: datetime
if TABLE_NAME in db.table_names():
db.drop_table(TABLE_NAME)
print("Table was deleted and will be overwritten.")
table = db.create_table(TABLE_NAME, schema=Skeet)
# this will automatically add and embed the items.
table.add(df.to_dicts())
table.create_fts_index("text", replace=True)
Plain RAG
In it's most pure form. Retrieval Augmented Generation has 3 simple components:
- Retrieve context (e.g., search)
- Build prompt
- Answer question
def search(question: str, top_k: int = 10) -> list[Skeet]:
return table.search(question).limit(top_k).to_pydantic(Skeet)
def build_prompt(question: str, context: list[Skeet]) -> str:
context_str = ""
for c in context:
context_str += f"- {c.text}\n======\n"
PROMPT = f"""
* You are an expert at answering questions from the user given a context.
* Use the context section to answer the questions from the user.
* Answer the question directly. No BS.
<context>
{context_str}
</context>
<question>
{question}
</question>
""".strip()
return PROMPT
def llm(prompt: str, model: str = LLM) -> str:
response = completion(
model=model,
messages=[{"content": prompt, "role": "user"}],
)
return response["choices"][0]["message"]["content"]
question = "What are the main reasons people are switching from twitter/X to bluesky?"
context = search(question)
prompt = build_prompt(question, context)
response = llm(prompt)
print("Question: ", question)
print(f"Answer: \n'{response}'")
# print(f"Context chunks:\n{context}")
Question: What are the main reasons people are switching from twitter/X to bluesky?
Answer:
'Based on the context, the main reasons people are switching from Twitter/X to Bluesky seem to be:
1. A desire for a more focused and curated experience, as mentioned in "Trying to be way more active here than Twitter..." and "My favorite thing about Twitter was looking at 'What's Trending'... Does that exist in Bluesky?"
2. Frustration with the chaos and noise on Twitter/X, as implied by "I feel like I’ve been neglecting Bluesky because I been on threads and it’s no different from IG but with Twitter capabilities .. 🤦🏾♂️" and "Everything all of the time is not what I ever asked for."
3. A sense of nostalgia for a more open and community-driven platform, as suggested by comparing Bluesky to Netscape in its early days.
4. A desire to support a more decentralized and less commercial social media platform, as implied by "i like to think of bluesky(tm) as like a netscape . wherein they end up spitting out something cool and popular and open (and - commercial) but do not really find long term business success from that."'
Great, that works. Now, what can we do more?
Complicating things: Hybrid Search
LanceDB also provides a nice hybrid search option - allowing us to use full text search in combination with semantic search. In the default configuration, it will weight vector similarity and full text search around 70-30.
All we need to do is add query_type='hybrid'
def hybrid_search(question: str, top_k: int = 10) -> list[Skeet]:
return table.search(question, query_type="hybrid").limit(top_k).to_pydantic(Skeet)
question = "What are the main reasons people are switching from twitter/X to bluesky?"
context = hybrid_search(question)
prompt = build_prompt(question, context)
response = llm(prompt)
print("Question: ", question)
print(f"Answer: \n'{response}'")
Question: What are the main reasons people are switching from twitter/X to bluesky?
Answer:
'Based on the context, the main reasons people are switching from Twitter/X to Bluesky include:
* The ability to see what's trending and have a better understanding of current events and public discourse
* Frustration with Twitter's content and moderation policies (as implied by the comment "it doesn't suck like x")
* A desire for more nuanced and complex discussions, as evidenced by the quote about people being more complex than we want to assume
* The presence of internet trolls on Twitter, who are also migrating to Bluesky
These factors seem to be driving users to leave Twitter/X and join Bluesky.'
Now, keep in mind. There are already at least 2 parameters we would need to tune and evaluate here. (1) the number of chunks we want to stuff in the context (here, top_k), and (2) the type of search we would like to conduct (hybrid, full-text, vector only).
But if that was not complicated enough, we could complicate a bit more!
What if we ask for a summary?
Let's look at the following question:
question = "Give me a high level summary of the skeets"
If we take the naive approach of simply embedding this query, we are likely going to retrieve context with skeets that are similar to our question. At the extreme, this will surface skeets that contain the words high level summary and skeets.
Now, this might be what we want, but likely isn't. What we want in this case is to provide more context to the LLM regarding topics that align with the overarching content of the skeets, and then let the LLM itself infer the high-level summary from the context.
The way I think about this is the notion of filters. Here's a quick drawing that illustrates the concept:
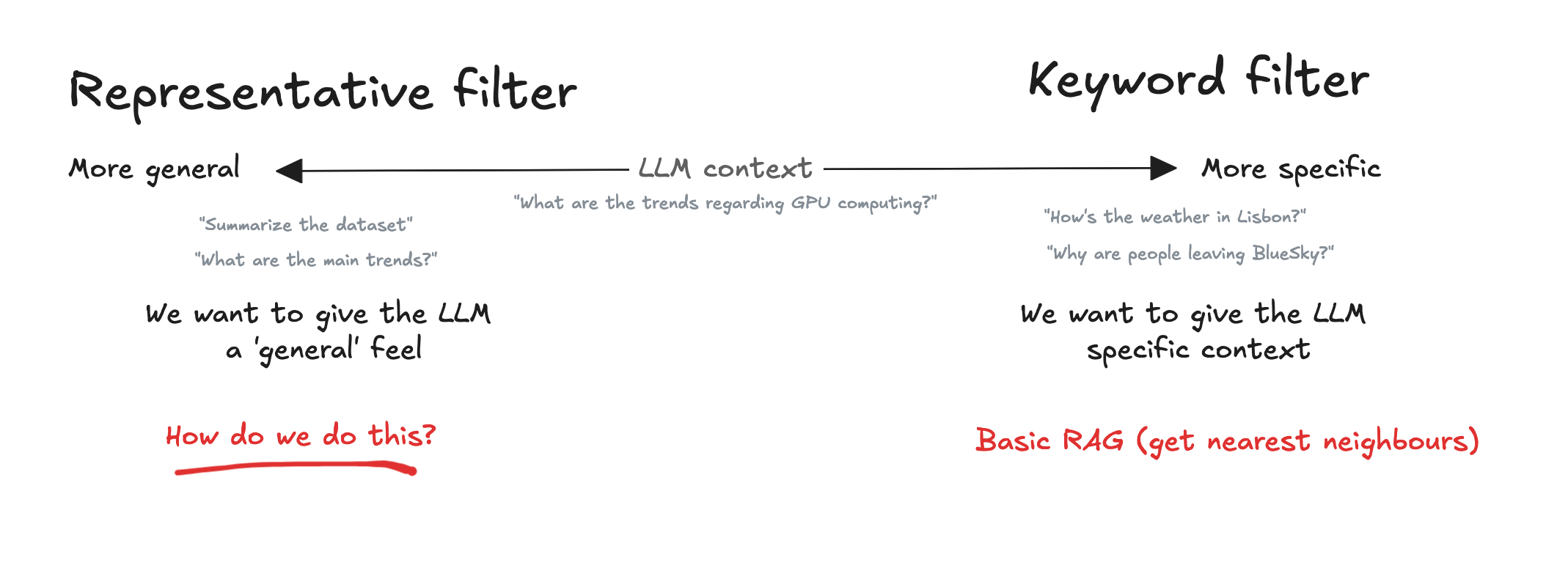
First of all, how do we detect if the user asks such a question?
Detecting representative questions
The most basic approach to detecting "representative" questions, is to use an LLM itself to handle them:
def get_intent(question: str):
INTENT_PROMPT = f"""
Tell me which filter we should use for the given user question.
The keyword filter filters data based on keywords from the question. This is good for specific questions or when you want to focus on a particular topic.
The representative filter returns a representative sample of insights, from which you can infer the answer to the question. This is good for questions that relate to the entire dataset (trends, summaries, etc)
Respond only with the type of filter to use!
Examples:
'Summarize the data' -> Representative filter
'What are the main insights?' -> Representative filter
'What are the high-level discussion points from our field reps regarding NOS ?' -> Keyword filter
'Describe the negative, neutral and positive perception of physicians for Benuron?' -> Keyword filter
'What are the main trends from the following skeets?' -> Representative filter
'What are the main trends?' -> Representative filter
'What are the key tweets I should be aware of?' -> Representative filter
Question: {question}
""".strip()
return llm(INTENT_PROMPT)
for question in [
"Summarize the skeets",
"What are the main trends in this dataset?",
"What's the current weather in Lisbon?",
"Why are people leaving Twitter/X?",
question,
]:
print(f"'{question}'", get_intent(question))
'Summarize the skeets' Representative filter
'What are the main trends in this dataset?' Representative filter
'What's the current weather in Lisbon?' Keyword filter
'Why are people leaving Twitter/X?' Keyword filter
'Give me a high level summary of the skeets' Representative filter
The LLM manages to understand if we need a general overview or a specific context quite well.
Answering questions that require the entire dataset in context
There's an interesting article that dives a bit more into this topic here. One idea I stole from there is the idea of passing a 'representative' sample of our dataset to the context.
Now how can we build a representative sample? Here's one idea:
- The user asks a general question that requires the whole dataset in context
- We know we can stuff a maximum of
Zchunks into the context - We retrieve a large number of embeddings from our dataset at random
- We run K-means clustering or something more fancy to cluster those embeddings into
Nclusters/topics - From each of those topics we draw
nitems so thatn * N ~= Z - We stuff those into the context
question
'Give me a high level summary of the skeets'
def get_representative_context(
max_items_context: int = 100, # max number of items to stuff in the context
n_clusters: int = 50, # number of clusters to create
n_items_initial_retrieval: int = 100_000, # number of items to retrieve from the database
) -> list[Skeet]:
"""
Retrieves a representative sample of items from the database to be used as context.
Args:
max_items_context (int): The maximum number of items to include in the context.
n_clusters (int): The number of clusters to create.
n_items_initial_retrieval (int): The number of items to retrieve from the database.
Returns:
list[Skeet]: A list of items from the database.
"""
items_per_cluster = int(max_items_context / n_clusters)
print(f"{items_per_cluster=}")
results_list = table.to_pandas()
if n_items_initial_retrieval < len(results_list):
results_list = results_list.sample(n_items_initial_retrieval).to_dict("records")
else:
results_list = results_list.to_dict("records")
results_list = [Skeet.model_validate(_) for _ in results_list]
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
embeddings = [_.vector for _ in results_list]
kmeans.fit(embeddings)
cluster_labels = kmeans.labels_
context_items = []
for cluster_id in list(set(cluster_labels)):
cluster_items = [
item
for index, item in enumerate(results_list)
if cluster_labels[index] == cluster_id
]
assert len(cluster_items) == list(cluster_labels).count(cluster_id)
context_items.extend(random.choices(cluster_items, k=items_per_cluster))
return context_items
context = get_representative_context()
print(llm(build_prompt(question, context)))
Based on the provided context, it appears that there are various "skeets" ( likely referring to Twitter threads or short conversations) scattered throughout the text. However, without further information, I can only provide a general high-level summary:
The skeets seem to be a collection of miscellaneous conversations and comments from various individuals on topics such as:
* Music and celebrities (e.g., Drake, Kendrick)
* Gaming and entertainment (e.g., League of Legends, Arcane)
* Politics and social issues (e.g., Trump, immigration)
* Pop culture references (e.g., references to movies, TV shows, or memes)
* Personal experiences and anecdotes (e.g., someone's spa date for their John Deere tractor)
These conversations seem to be a mix of humorous, sarcastic, and serious discussions. If you'd like me to provide more specific information about any particular skeet, please let me know!
There are a lot of ways we could make this better. But this is the basic idea.
Expanding user queries
Another interesting concept is the concept of query expansion. I read this one in the LLM Engineer's Handbook. It's a great book - you should read it to!
In this case we use an LLM to expand the user query in hope of retrieving even more relevant items into our context. Here's how it works:
def expand_query_for(question: str, expand_to_n: int = 5) -> list[str]:
# could be much better by using json mode, structured outputs, or any of these: https://simmering.dev/blog/structured_output/
EXPAND_QUERY_PROMPT = f"""
* You are an AI language model assistant.
* Your task is to generate {expand_to_n} different versions of the given user question to retrieve relevant documents from a vector database.
* By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search.
* Return a json string with a 'questions' key, which is a list of strings. It should be parseable by json.loads in Python.
* IMPORTANT: Do not include ```json or any other text in the response.
Original question:
'{question}'""".strip()
response = llm(EXPAND_QUERY_PROMPT)
questions = json.loads(response)["questions"] + [question]
return questions
question = "What are the main reasons people are switching from twitter/X to bluesky?"
expanded_questions = expand_query_for(question)
for q in expanded_questions:
print(f"- '{q}'")
- 'Why did users leave Twitter and join Bluesky?'
- 'What factors contribute to the migration of users from X (formerly Twitter) to Bluesky?'
- 'Identify the key drivers behind the shift from Twitter to Bluesky, based on user behavior and preferences'
- 'What are the primary reasons users are abandoning their old social media accounts on Twitter/X and joining a new platform like Bluesky?'
- 'How does the user experience and feature set of Bluesky differ from that of Twitter/X, leading to increased adoption?'
- 'What are the main reasons people are switching from twitter/X to bluesky?'
We can now take these questions, do a retrieval for each one of them, and answer the question.
context = []
for q in expanded_questions:
context.extend(search(q))
print(f"Question: {question}")
print(f"Answer:\n{llm(build_prompt(question, context))}")
Question: What are the main reasons people are switching from twitter/X to bluesky?
Answer:
Based on the context provided, the main reasons people are switching from Twitter/X to Bluesky include:
1. **Frustration with Twitter/X**: Many users express their dissatisfaction with the current state of Twitter/X, mentioning issues like transphobia, rampant engagement farming, and the platform's overall toxic environment.
2. **Desire for a more positive experience**: Users are seeking an alternative where they can engage with others in a more constructive and respectful manner. This is evident from statements like "it doesn't suck like x (twitter)" and "y'all are lovely."
3. **Wish to preserve the original spirit of Twitter**: Some users nostalgically recall the early days of Twitter, when it was more open, popular, and user-friendly. They hope Bluesky will emulate this spirit.
4. **Attractiveness of new features or improvements**: Although not explicitly stated, some users might be drawn to specific features or improvements that Bluesky offers compared to Twitter/X.
Overall, the main reasons people are switching from Twitter/X to Bluesky seem to be a combination of dissatisfaction with the current state of the former and a desire for a better alternative.
The most important Lesson
These are all fancy and nice. But make sure to always start with a baseline. A simple one.
Resources to go beyond the basics
- Most things by Jason Liu are great
- Arcturus labs has some good writing on the topic
- Simon Willison's entries are always worth a skim/read
- LLM Engineer's handbook from Paul Iusztin and Maxime Labonne
- I'm currently reading relevant search
- Handling vision in RAG
- This talk by Ben Clavié
- Most of these talks from Parlance labs
- Evaluate rag with RAGAS
- This blog post by Goku Mohandas
- This talk by Sam Partee