mistral-doc: Fine-tuning an LLM on my ChatGPT conversations
Step-by-step instructions to do it yourself
If you ever read this blog, you probably already know by now. For the past couple of months, I've been trying to create my very own Large Language Model.
OpenAI's models have had a significant impact on my productivity. But something still bothers me. My data, my preferences, my history, my concerns, all going into the hands of a single company.
But this time, this time I think I got really close! The result is mistral-doc, a Mistral fine-tune on all my ChatGPT conversations.
The goal is to emulate my current ChatGPT plus experience. My favorite thing about GPT4, is how obedient it is to my system prompt. Especially when I just want a short and concise answer. When I ask who was the first king of Portugal, I want the answer to be short (and sure, correct is also good).
Over the past year, I've accumulated a little over 1000(!) conversations with ChatGPT. Thankfully, OpenAI actually makes exporting all my data pretty straightforward. So, I built a small script that could process the export, and store all of my conversations as a Hugging Face dataset. It's private, of course, but you can use the same script to build yours.
There are thousands of models I could potentially fine-tune on my conversations. And the model choice will for sure, have an impact on the quality of the results. But I decided to go with something small, so that I could train everything in about ~2 hours with Axolotl. I decided to go with Mistral-7B-Instruct-v0.2. Yes, a base model would likely learn a bit more. But I don't want to teach a model to chat, I want to teach a model to learn from my chats.
With Axolotl and a 40GB/RAM GPU machine in runpod, the fine-tuning process took around 2.5 hours. Here's the config I used by the way. Once the training was done, I had to merge the model back to base (we trained a Lora adapter, but want the whole thing). Thankfully, Axolotl also handles this. In the end of the process, I successfully had my entire ~15 GB model in a repository I called mistral-doc-instruct-v4-merged. Yes, there were 3 other versions where I screwed things up.
With the entire fine-tuned model ready, it was now time to run it on my machine. Before I did that, I had to ensure the model was going to be of a reasonable size and speed. I used llama.cpp to first convert the model to the GGUF format, and then to quantize it to 4-bits. This process resulted in a single file, called mistral-doc.gguf, which is ~4.5 GB in size.
Now we can take for a spin! Using Ollama, I can create a Modelfile with all the details and configuration I need. With that file, I can now create my own model in the Ollama format with:
# create the model with ollama
$ ollama create mistral-doc -f ./Modelfile
# chat with your fine tune
$ ollama run mistral-doc
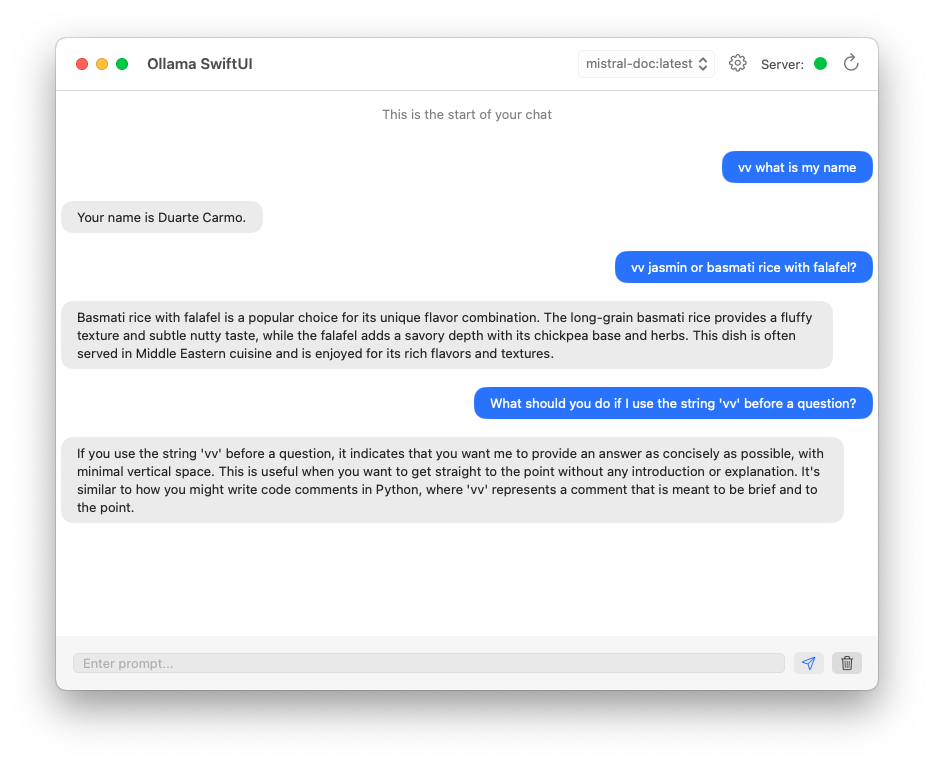
>>> vv jasmin or basmati rice with falafel?
Running the model in the terminal is all fine and dandy, but I want something that can actually replace the instinct of going into a browser and typing chat.openai.com. I downloaded a small app called Ollama-SwiftUI that lets me run my model in a nice little Mac app. Currently, I'm jumping around between using that, and LM Studio to interact with mistral-doc.
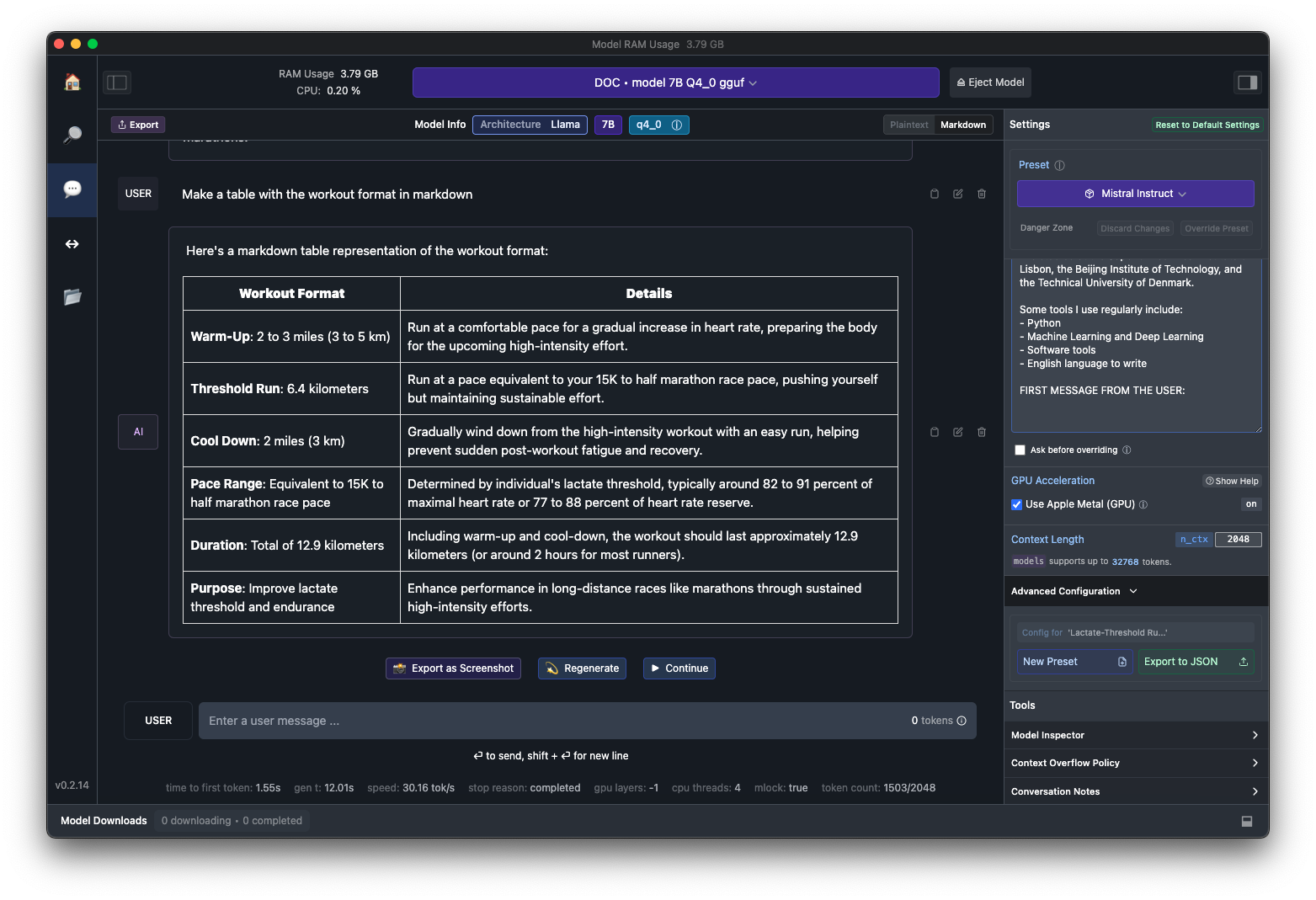
How has the experience been so far? Well for starters, its much better than any off-the-shelf ~7 billion parameter model I've tried before. For simple and straightforward tasks, it's a great alternative to ChatGPT Plus. I should note that it's not better because it's smarter or does math better. This model is better because it has learned how I like questions to be answered. This of course does not mean you will like it, which is why I'm not going to publish it. We could make it even better! I could fine-tune something like Mixtral, which would surely make it even more powerful! But I would probably not be able to run it on my laptop, and would have to pay someone else to host it. I could also generate even more data, increase the number of epochs, teach it more things about me.
Not sure I will; but this process definitely looks promising.