MCPs are mostly hype
..but they can also be a lot of fun. If you work in tech, I'd say there's a 98% chance you've heard about it. MCPs are the future of agents, MCPs will be everywhere, MCPs are the future. The Model Context Protocol, first introduced by Anthropic is blowing up. For both good and bad reasons.
For me, as always, I refrain from judgement before taking anything for a spin. At the end of the day, MCP is a standardized way of giving access to tools to an LLM. Those tools come in the form of function calling. So nothing groundbreaking.
I've tested a few MCP servers. Adding the Gitlab MCP server to Zen, adding the Polars docs MCP to Claude, adding a TickTick (my todo list) MCP server to Bolt. They all worked sometimes. And in computers, when something works sometimes, well - I prefer using something else.
As the training for Oslo ramps up, I've once again felt the need to give an LLM access to "the outside world".
Accessing my training textbooks
For Oslo (and for the past 3 years) - I've been following Phitzinger's training methodology. In short, I believe mostly in volume. I have the pdf version of the book, it's great. Whenever I dropped the book into any of the LLM/Chat apps, I almost always got the same "context is full" or "too many tokens within X mins" message.
I don't want the LLM to access the whole book. I want it to access some parts of the book. If your mind jumps straight to RAG, let me stop you right there. It's not RAG, it's search. We don't want a whole vector database. We don't want a whole retrieval system. We want keyword search, over my book. That's it.
def prep_book() -> tuple[BM25Okapi, list[str]]:
script_dir = Path(__file__).resolve().parent
# uvx --from "markitdown[pdf]" markitdown marathon.pdf > marathon.md (make it a md file)
book = script_dir / "marathon.md"
with open(book, "r", encoding="utf-8") as file:
content = file.read()
words = content.split()
corpus = []
chunk_size_words = 800
overlap = int(chunk_size_words * 0.2)
for i in range(0, len(words), chunk_size_words - overlap):
corpus.append(" ".join(words[i : i + chunk_size_words]))
tokenized_corpus = [doc.split(" ") for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
return bm25, corpus
def search_marathon_training_book(
query: str,
total_results: int = 10,
) -> str:
"""
Search the marathon training book for a specific query.
Args:
query (str): The search query.
total_results (int): The number of results to return. (default: 10)
"""
bm25, corpus = prep_book()
tokenized_query = query.split(" ")
results = bm25.get_top_n(tokenized_query, corpus, n=total_results)
results_as_bullets = "\n".join(
f"<result_{i + 1}>\n...{result}...\n</result_{i + 1}>"
for i, result in enumerate(results)
)
return f"""
<search_marathon_training_book>
<search_query>{query}</search_query>
{results_as_bullets}
</search_marathon_training_book>
""".strip()
Accessing my training plan
Now that we have a function to access my training "philosophy", we also need the LLM to be able to access my training plan. I'm a simple guy, I like my training plan in my calendar. It's one less tool I need to use. Well - we can also give the LLM access to my calendar's ics file. We can just call the get_training_program_events and access the training events within a time range. Simple, effective.
def get_training_program_events(start_date: str, end_date: str) -> str:
"""
Fetches the athlete's training program events in the date range specified.
Args:
start_date: Start date in format "DD-MM-YYYY"
end_date: End date in format "DD-MM-YYYY"
Returns:
A string with matching VEVENTS in XML-like format.
"""
start = datetime.datetime.strptime(start_date, "%d-%m-%Y").replace(
tzinfo=ZoneInfo("UTC")
)
end = datetime.datetime.strptime(end_date, "%d-%m-%Y").replace(
tzinfo=ZoneInfo("UTC")
)
ics_path = Path(__file__).parent / "oslo_training_plan.ics"
ics_content = ics_path.read_bytes()
cal = Calendar.from_ical(ics_content)
events_xml = []
def to_datetime(val: datetime.datetime | datetime.date) -> datetime.datetime:
if isinstance(val, datetime.date) and not isinstance(val, datetime.datetime):
return datetime.datetime.combine(
val, datetime.time.min, tzinfo=ZoneInfo("UTC")
)
if val.tzinfo is None:
return val.replace(tzinfo=ZoneInfo("UTC"))
return val
for component in cal.walk():
if component.name != "VEVENT":
continue
dtstart = to_datetime(component.decoded("DTSTART"))
dtend_raw = component.get("DTEND")
dtend = to_datetime(component.decoded("DTEND")) if dtend_raw else None
if dtend is None or not (start <= dtstart <= end or start <= dtend <= end):
continue
summary = component.get("SUMMARY", "")
location = component.get("LOCATION", "")
events_xml.append(f"""<event>
<summary>{summary}</summary>
<location>{location}</location>
<start>{dtstart.isoformat()}</start>
<end>{dtend.isoformat()}</end>
</event>""")
return "<events>\n" + "\n".join(events_xml) + "\n</events>"
Checking my runs
The LLM also needs to be able to compare the planned training sessions to the actual runs I've made (you know - to keep me in check, or give me feedback). The easiest (NOT the safest) way to do this is to use the garminconnect library. We can also wrap that up in a simple function:
def fetch_athlete_runs(lookback_days: int) -> str:
"""
Fetch athlete's running activities from Garmin Connect.
Args:
lookback_days (int): Number of days to look back for running activities.
"""
garmin = start_garmin()
today = datetime.date.today()
startdate = today - datetime.timedelta(days=lookback_days)
activities = garmin.get_activities_by_date(
startdate.isoformat(), today.isoformat(), activitytype="running"
)
sorted_runs = sorted(activities, key=lambda x: x["startTimeLocal"], reverse=True)
output = ["<Runs>"]
for run in sorted_runs:
start_time = run["startTimeLocal"]
distance_km = round(run.get("distance", 0) / 1000, 2)
duration_sec = run.get("duration", 0)
duration_fmt = str(datetime.timedelta(seconds=int(duration_sec)))
avg_hr = run.get("averageHR", "n/a")
pace_sec_per_km = duration_sec / distance_km
pace_min = int(pace_sec_per_km // 60)
pace_sec = int(pace_sec_per_km % 60)
pace = f"{pace_min}:{pace_sec:02d} min/km"
output.append(f""" <Run>
<Date>{start_time}</Date>
<Distance>{distance_km} km</Distance>
<Duration>{duration_fmt}</Duration>
<Pace>{pace}</Pace>
<HeartRate>{avg_hr} bpm</HeartRate>
</Run>""")
output.append("</Runs>")
return "\n".join(output)
Putting it all together
Our goal would be to give an LLM access to all these tools at the same time, and let it analyze and give me feedback on my training. MCP is supposed to solve just that - putting all your tools in a single place. This is the moment where we would start developing our complicated 12-factor MCP architecture. But instead of doing that, why don't we just use uv scripts?
The only thing to do, is to drop all the functions we want to give an LLM in a single file. With that in place, we can run uv run oslo_marathon_mcp.py
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "mcp[cli]",
# "garminconnect",
# "rank-bm25",
# "icalendar",
# ]
# ///
from mcp.server.fastmcp import FastMCP
from rank_bm25 import BM25Okapi
from garminconnect import Garmin
from pathlib import Path
import datetime
from icalendar import Calendar
from zoneinfo import ZoneInfo
MCP = FastMCP("oslo_marathon")
@MCP.tool()
def search_marathon_training_book(
query: str,
total_results: int = 10,
) -> str:
"""
Search the marathon training book for a specific query.
Args:
query (str): The search query.
total_results (int): The number of results to return. (default: 10)
"""
...
@MCP.tool()
def fetch_athlete_runs(lookback_days: int) -> str:
"""
Fetch athlete's running activities from Garmin Connect.
Args:
lookback_days (int): Number of days to look back for running activities.
"""
...
@MCP.tool()
def get_training_program_events(start_date: str, end_date: str) -> str:
"""
Fetches the athlete's training program events in the date range specified.
Args:
start_date: Start date in format "DD-MM-YYYY"
end_date: End date in format "DD-MM-YYYY"
Returns:
A string with matching VEVENTS in XML-like format.
"""
...
@MCP.tool()
def get_current_date() -> str:
"""
Returns the current date in ISO format.
"""
return datetime.datetime.now(tz=ZoneInfo("UTC")).isoformat()
if __name__ == "__main__":
MCP.run(transport="stdio")
Our MCP is ready. There are just short of 8984 ways to use an MCP server with an LLM. My favorite one is still BoltAI. We open our MCP server configuration and add our nice little MCP server:
{
"mcpServers" : {
"oslo_marathon" : {
"args" : [
"run",
"/Users/duarteocarmo/Repos/scripts/oslo_marathon_mcp.py"
],
"command" : "uv"
}
}
}
One of the nice features of BoltAI, is the ability to create "projects". These are similar to the projects feature of ChatGPT. In short, BoltAI gives you the ability to create a template that will be used for a group of chats. I created a "Running" project where I defined the model I'd like to use, as well as the oslo_marathon MCP server. BoltAI also gives you the ability to investigate the MCP server to quickly check what tools are made available to the LLM.
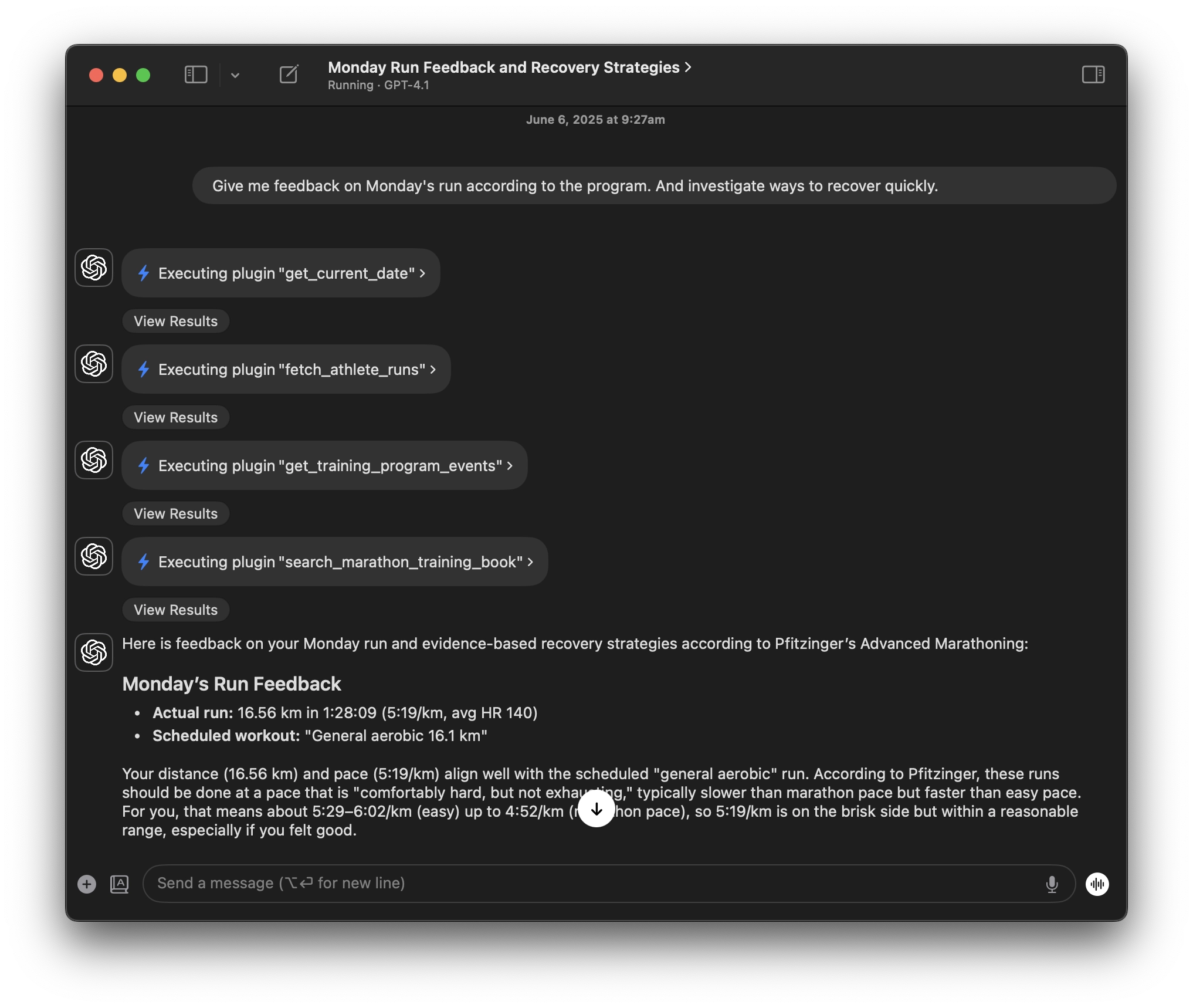
Finally, once everything is configured, we can now ask the LLM something very specific according to my run. And as you can see, the LLM will call all the necessary tools in order. Just like the ReAct paper introduced - the LLM now gives us much more contextualized information about my run, and searches the Pfitzinger training book for information on recovering strategies.
Final thoughts
For the past months, I've seen many people talking about MCP (and even A2A) as things that will revolutionize AI and how we interact with LLMs. As always, there's A LOT of claims out there about what these protocols can do, and the promise they carry. It's hype and over-excitement in its purest form.
I can't help but cringe sometimes when I see a big tech CTO talking about their incredibly great MCP server. For the rest of us that work in the industry. MCP is just a list of functions we give the LLM access to, wrapped in a FastAPI server.
And we can't deny. Tool calling is incredibly powerful, but it's still tool calling. Tools should be targeted, well described, and made easy to understand by the Large Language Model. It's not about throwing a hammer around in a dark room and hoping that it will pick up an API call that was designed for programmers - it's about giving LLMs the right access in a controlled manner.
Don't be fooled. You don't need to download one of the thousands of MCP servers of dubious quality and security. You can just create a 200 line Python file and give it to the LLM, it has the same (probably better) effect.