Faísca: The modern LLM stack in a single script
Why do this?
ML and AI are moving at an incredible pace. The amount of research coming out vastly surpasses anyone's ability to interiorize it. By interiorize I mean study, experiment, or even just test it out. However, the importance of learning has never been greater. Even if we don't really know what the future looks like, time studying, reading, and building is never wasted.
I've always preferred pragmatic resources over theoretical ones. I learn best by doing. Resources like Andrej's minGPT and Raschka's LLM from scratch series are the ones I learn best from. So, I decided to build my own minimal implementation of an LLM that captures most of the concepts around "modern" training. It's called: Faísca1.
Faísca is an implementation of the "modern" LLM stack in a single script of around ~1000 lines of code. All you need to start training is uv:
uv run https://raw.githubusercontent.com/duarteocarmo/faisca/refs/heads/master/faisca_torch.py
I built it as an educational resource I can hack on over time. Right now, it trains a model that generates newspaper headlines in Portuguese. Simple? Absolutely. It's by no means comparable to ChatGPT. Faísca has only 13 million parameters. (For context, GLM 4.6 - the best performing open source model in LMArena - has ~355 billion2: Faísca is ~27.000 times smaller)
If you just want the code, it's here. For the rest, let me walk you through how it works.
A small dataset of news headlines
Faisca can work with any dataset. For this example, I started with something close to my heart: Portuguese. I built a dataset that filters Common Crawl News for only 2016. The resulting dataset has 1.8 million headlines from publications around the world.
I also kept the language identified from Common Crawl as well as the original url.
GPT2 in PyTorch
FaiscaGPT is inspired by both minGPT and LLM-from-scratch. It's a mix that implements the GPT2 architecture using only PyTorch (the only dependency). At the core, you'll notice the Transformer Block with MultiHeadedAttention. In the vanilla state, the transformer block has 4 heads, an embedding dimension of 128, and 4 layers. This means the whole thing is around 13 million parameters (e.g., should run fine in modern MacBooks!)
class TransformerBlock(nn.Module):
def __init__(
self,
embedding_dimension: int,
num_heads: int,
qkv_bias: bool,
dropout_rate: float,
):
super().__init__()
self.attention = nn.MultiheadAttention(
embed_dim=embedding_dimension,
num_heads=num_heads,
dropout=dropout_rate,
bias=qkv_bias,
batch_first=True,
)
self.feed_forward = FeedForward(
embedding_dimension=embedding_dimension,
)
self.norm1 = nn.LayerNorm(embedding_dimension)
self.norm2 = nn.LayerNorm(embedding_dimension)
self.drop_shortcut = nn.Dropout(p=dropout_rate)
class FaiscaGPT(nn.Module):
def __init__(
self,
config: Config,
):
super().__init__()
self.token_embedding = nn.Embedding(
config.vocab_size, config.embedding_dimension
)
self.positional_embedding = nn.Embedding(
config.context_length, config.embedding_dimension
)
self.dropout_embedding = nn.Dropout(p=config.dropout_rate)
self.transformer_blocks = nn.Sequential(
*[
TransformerBlock(
embedding_dimension=config.embedding_dimension,
num_heads=config.num_heads,
qkv_bias=config.qkv_bias,
dropout_rate=config.dropout_rate,
)
for _ in range(config.num_layers)
]
)
self.final_layer_norm = nn.LayerNorm(config.embedding_dimension)
self.out_head = nn.Linear(
config.embedding_dimension, config.vocab_size, bias=False
)
n_params_all = sum(p.numel() for p in self.parameters())
n_params_all_million = n_params_all / 1e6
print(f"Total number of params: {n_params_all_million:.2f}M")
If this is too big/small for you, you can tweak the settings in the config. I wanted something powerful, mostly bug-free (I hope), and that isn't overwhelming for someone to tweak it.
That's nice and all, but what about training?
Pre-training headlines in Portuguese
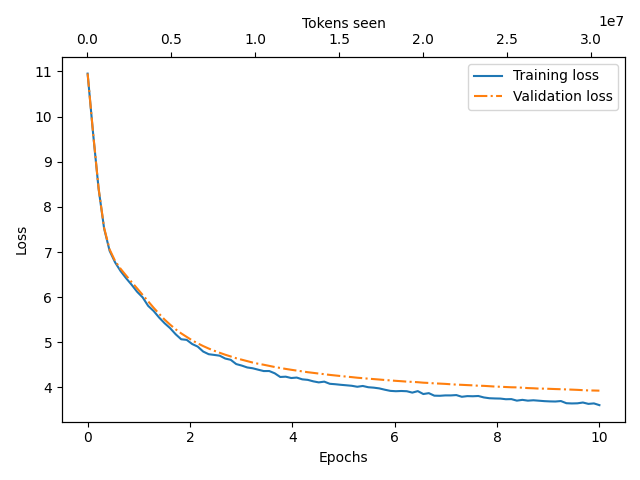
The first phase is pre-training. We filter the dataset for headlines in the Portuguese language. We then train on around 30K headlines over 10 epochs. At the start the model outputs gibberish, eventually settling into something more coherent. Even if not grammatically correct, it certainly looks plausible.
If we wanted to make it speak perfect Portuguese, we would train it on more data for longer (following the Chinchilla law, the optimal training data for such a model would be around 250M tokens). But that's not the goal of this exercise. However, I did notice a strong bias towards Brazilian Portuguese - expected, since it's the most common variant of Portuguese.
...
Epoch: 8 - Step: 1540 - Train Loss: 3.7417 - Validation Loss: 4.0037 - Batch: 37 / 188 - Tokens seen: 25247744
Epoch: 8 - Step: 1560 - Train Loss: 3.7077 - Validation Loss: 4.0016 - Batch: 57 / 188 - Tokens seen: 25575424
Epoch: 8 - Step: 1580 - Train Loss: 3.7250 - Validation Loss: 3.9938 - Batch: 77 / 188 - Tokens seen: 25903104
Epoch: 8 - Step: 1600 - Train Loss: 3.7074 - Validation Loss: 3.9858 - Batch: 97 / 188 - Tokens seen: 26230784
Epoch: 8 - Step: 1620 - Train Loss: 3.7159 - Validation Loss: 3.9816 - Batch: 117 / 188 - Tokens seen: 26558464
Epoch: 8 - Step: 1640 - Train Loss: 3.7063 - Validation Loss: 3.9745 - Batch: 137 / 188 - Tokens seen: 26886144
Epoch: 8 - Step: 1660 - Train Loss: 3.6965 - Validation Loss: 3.9735 - Batch: 157 / 188 - Tokens seen: 27213824
Epoch: 8 - Step: 1680 - Train Loss: 3.6909 - Validation Loss: 3.9691 - Batch: 177 / 188 - Tokens seen: 27541504
**** GENERATION 1 OF 1 ****
> 'Presidente com o que os quase 3 milhões de seução'
> 'Governo para ao de fazer em São de casação deixa'
> 'Cânia de caminhão do ensino, diz que veítica de lider'
*************************
Epoch: 9 - Step: 1700 - Train Loss: 3.6883 - Validation Loss: 3.9643 - Batch: 9 / 188 - Tokens seen: 27869184
Epoch: 9 - Step: 1720 - Train Loss: 3.6987 - Validation Loss: 3.9607 - Batch: 29 / 188 - Tokens seen: 28196864
Epoch: 9 - Step: 1740 - Train Loss: 3.6507 - Validation Loss: 3.9561 - Batch: 49 / 188 - Tokens seen: 28524544
...
But how could we direct the model towards more of a Portuguese from Portugal? Enter our second training stage.
Supervised fine-tuning (SFT) on Portuguese from Portugal
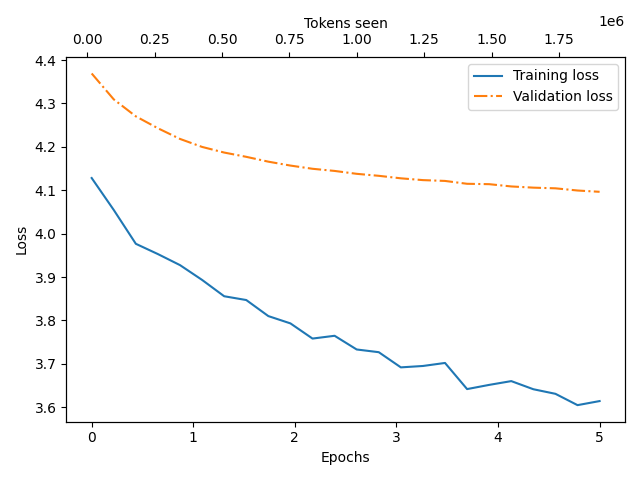
Supervised fine-tuning is just more training. In the case of ChatGPT and variants this is where the models get on multi-turn conversations. In our case though, we want something slightly different.
We re-filter the training data to include only headlines from websites that finish with .pt, to make sure they're from Portugal. And we then train for about 5 epochs of 20K titles. And guess what? The effect is noticeable! After just a couple of epochs, the model's text feels much more like Portuguese from Portugal than Brazil (words like "Cristiano", "Portugal", the accents, and the tone).
...
Epoch: 3 - Step: 85 - Train Loss: 3.6417 - Validation Loss: 4.1149 - Batch: 14 / 24 - Tokens seen: 1409024
Epoch: 3 - Step: 90 - Train Loss: 3.6514 - Validation Loss: 4.1140 - Batch: 19 / 24 - Tokens seen: 1490944
Epoch: 3 - Step: 95 - Train Loss: 3.6601 - Validation Loss: 4.1088 - Batch: 24 / 24 - Tokens seen: 1572864
**** GENERATION 1 OF 1 ****
> 'Presidente-se ao de Festa'
> 'Actualidade: «Novação da Saúbal e um mortos'
> 'Actualidade: "Aumento deixação ao de atentado em Portugal'
> 'Actualidade: «Papa Francisco é'
*************************
Epoch: 4 - Step: 100 - Train Loss: 3.6414 - Validation Loss: 4.1060 - Batch: 5 / 24 - Tokens seen: 1654784
Epoch: 4 - Step: 105 - Train Loss: 3.6308 - Validation Loss: 4.1045 - Batch: 10 / 24 - Tokens seen: 1736704
Epoch: 4 - Step: 110 - Train Loss: 3.6047 - Validation Loss: 4.0994 - Batch: 15 / 24 - Tokens seen: 1818624
Epoch: 4 - Step: 115 - Train Loss: 3.6141 - Validation Loss: 4.0964 - Batch: 20 / 24 - Tokens seen: 1900544
**** GENERATION 1 OF 1 ****
> 'Presidente: «Quero e ao de mais devembia'
> 'Fernando de ano como de saíria'
> 'Actualidade: Pelo com ao de mais de Berlim foições'
> 'Cristiano Oriental: «Estamos'
*************************
...
What if we wanted to direct our model even more? What if all we wanted was football related headlines? Enter our final phase.
Reinforcement Learning (GRPO) for sports news
The last phase is all about reinforcement learning (RL). The cherry on top of the cake that made ChatGPT so popular. A couple of years ago we needed to have some sort of preference data to do reinforcement learning. In the last couple of years - as LLMs got more popular - other RL techniques came to fruition. Techniques like Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO) started popping up (more reading here).
Recently, DeepSeek took the world by storm and came up with Group Relative Policy Optimization (GRPO). GRPO speeds up things compared to other RL techniques by removing the need for a critic model. Instead, we sample a group of candidate responses from our LLM, score them using a "reward function", and use those scores to update the model towards the "good responses". In short, we need much less memory to optimize.
Another beautiful thing about this technique is that we only need a single function to optimize our model:
def calculate_reward_for(text: str) -> float:
target_words = [
"futebol",
"benfica",
"porto",
"sporting",
"bola",
"liga",
# ...
]
has_word = set(text.lower().split()).intersection(set(target_words))
return 1.0 if has_word else 0.0
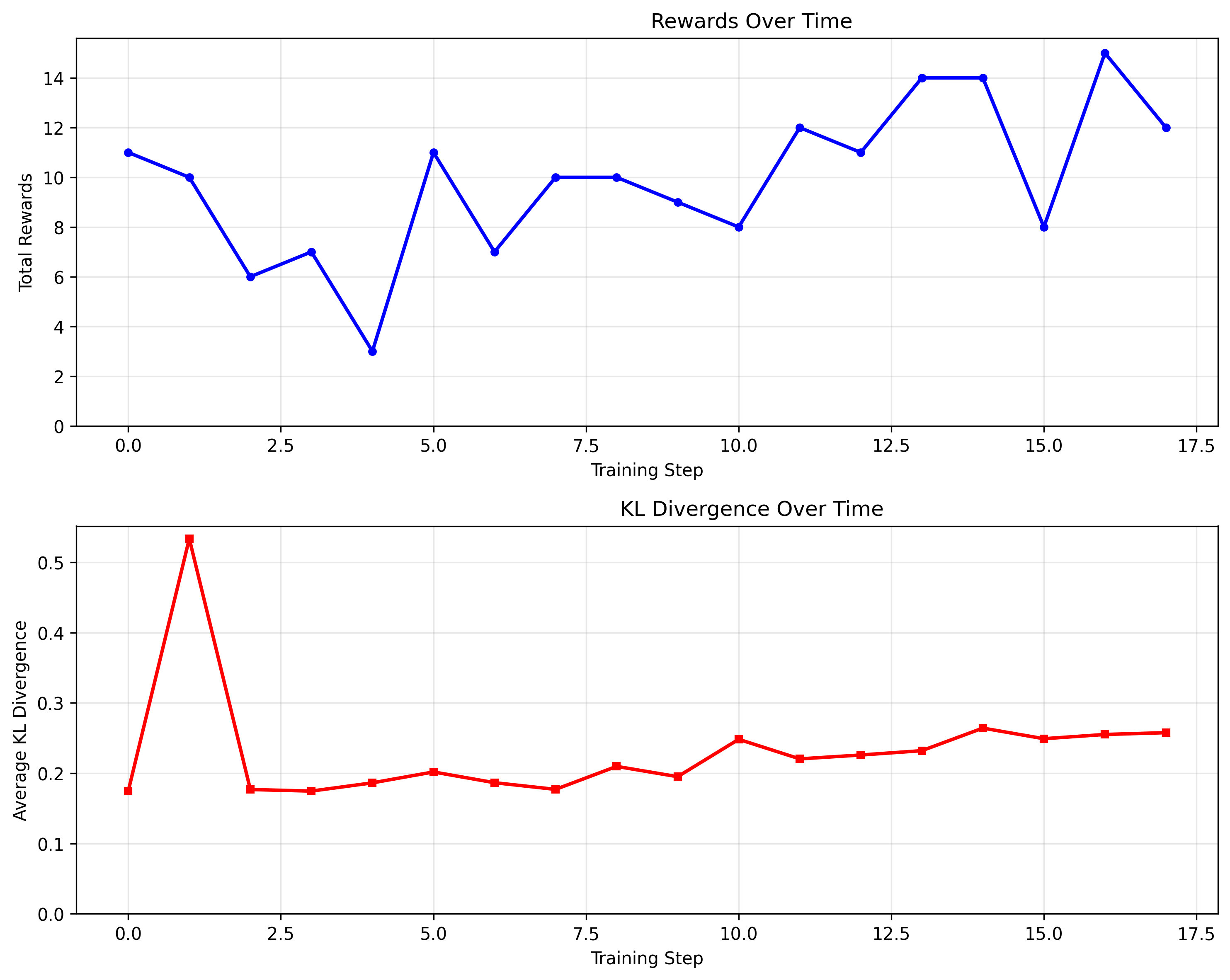
That's it. That's enough to kick start the training process for our tiny model. In the graph above you see the rewards increase for every training step, as well as the KL divergence (that shows us how much the probability distribution shifts from the original).
In practice, our model is now much more likely to generate headlines related to football - for which it was rewarded. It now mentions words like "Real Madrid" much more often!
...
3: kl= 0.2592, grad_norm= 0.7413
Processing experience 1 of 2
3: kl= 0.1728, grad_norm= 0.9851
Step 17 generated 24 completions
=== Sample completions ===
> Mais fé aos de lado pesso dização com o Governo que mais velho
> Mais o FC Porto de um luta contra o mundo aumento com o Sporting
> Mém o que faz apoi vivemio e agora do BES: «Quase um ligação do mundo de trabalho
> Sporting a todos os jogadores ao Real Madrid
=========================
Returns: 16.00/24
Returns of step 17: 16.0000
Processing experience 0 of 2
0: kl= 0.2157, grad_norm= 0.8532
...
Final thoughts & Acknowledgements
This was a pretty fun project to hack on, and took a longer than expected. I have some ideas for expanding it, and perhaps make a more Apple-Native version by using MLX. Potentially, we could also create a Mixture of Experts variant.
The repo is 100% open source - feel free to fork it, hack on it, and adapt it to your needs! If you find bugs, don't hesitate to submit a PR.
Finally, I want to acknowledge the great projects that inspired this work:
- minGPT from Andrej Karpathy
- LLMs from Scratch - Sebastian Raschka
- RLFromScratch - Ming Yin
- minRLHF - Tom Tumiel