Classification in the age of LLMs: The emoji problem

For the past years Vitto and I have used Tricount to track our shared expenses. The app is actually pretty good, but there’s one small thing that annoys me quite a bit.
Even though we spoke English to each other for the first month, we’ve since spoken a mix of Italian and Portuguese. And when I say a mix, I really mean a mix. I mean, would you just look at our expense tracking app:
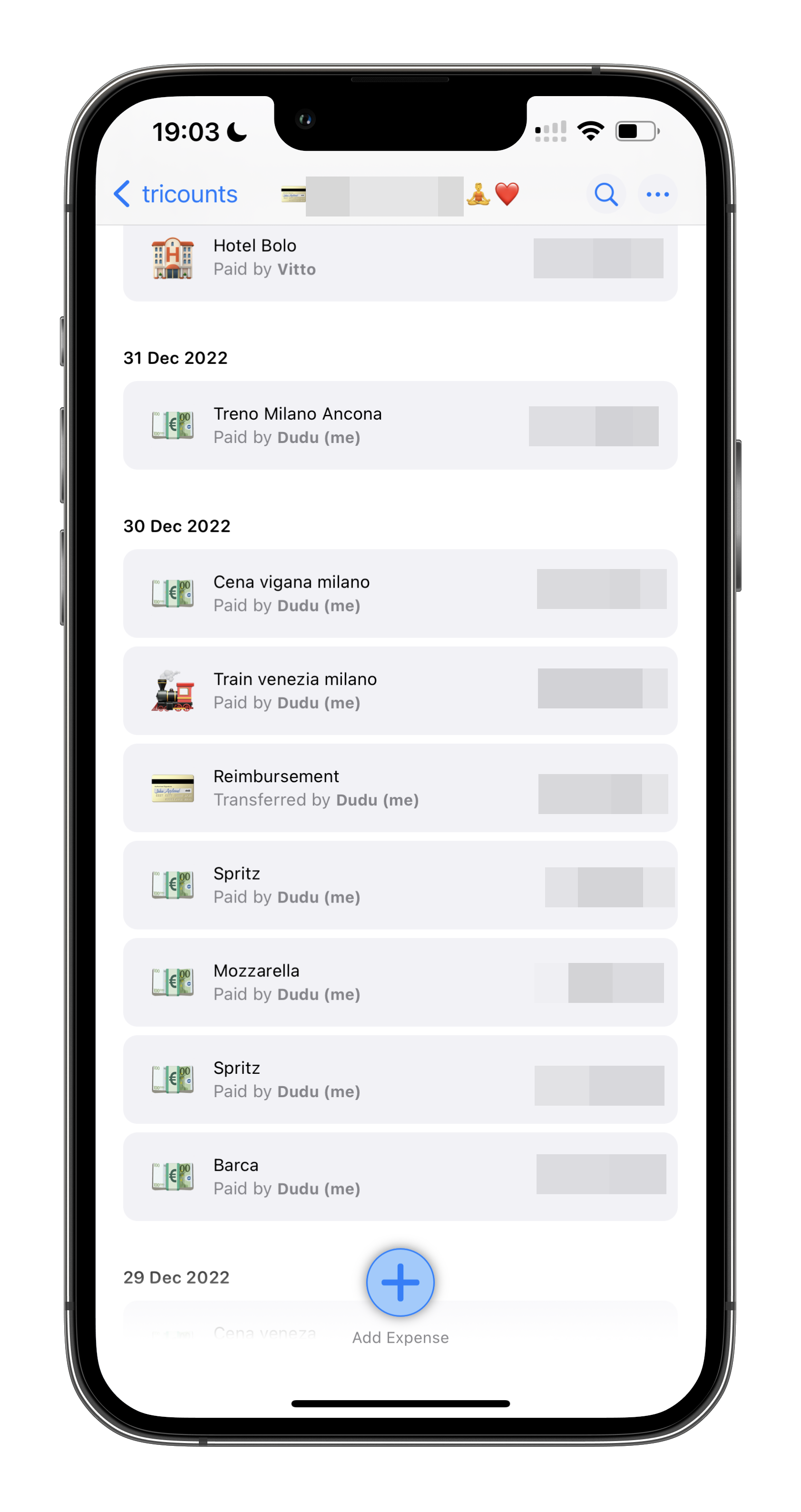
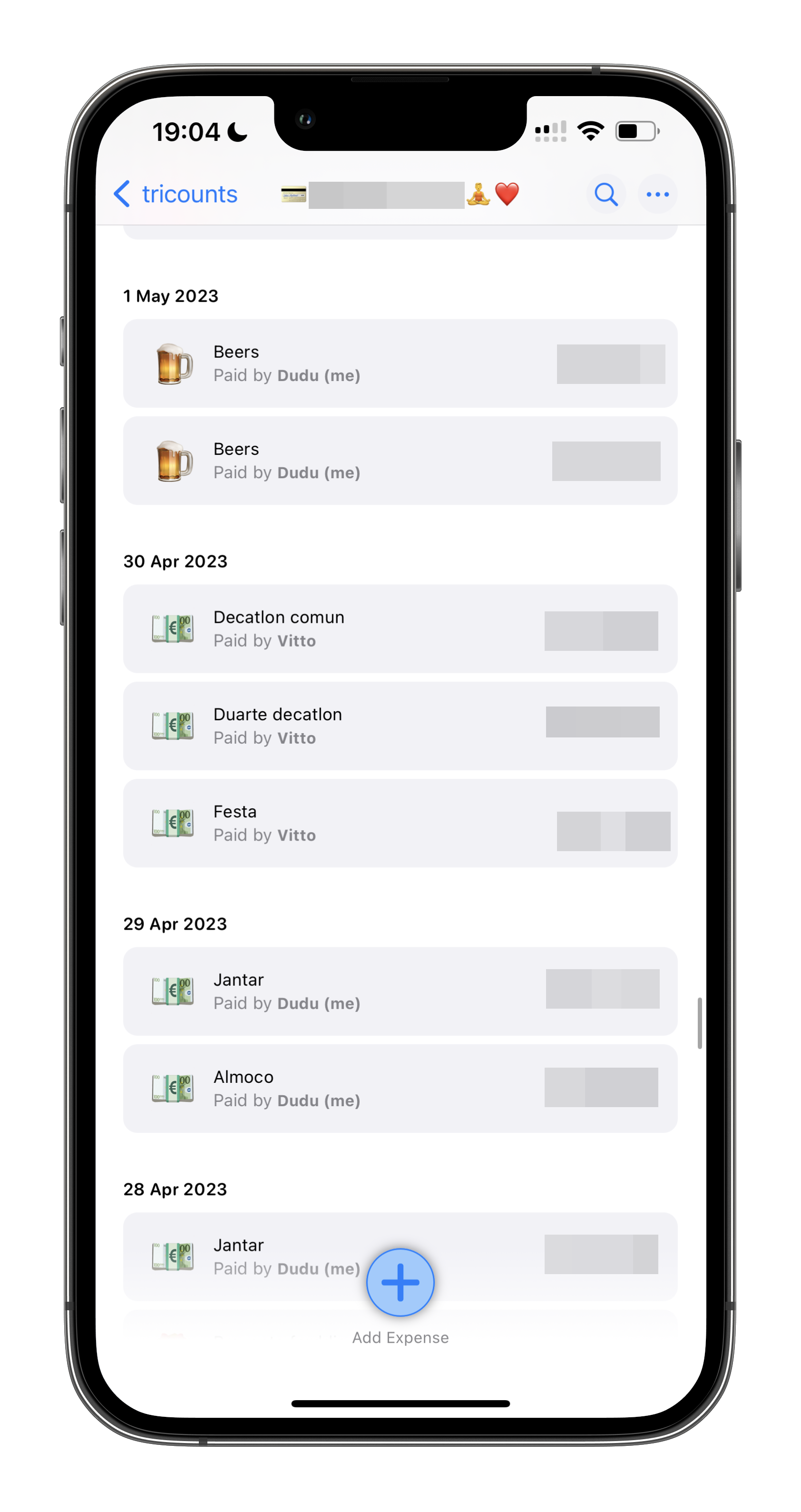
For the average calm and relaxed reader, this might not seem like much. But for us, other folk, it’s extremely annoying to see how it misses assigning the right emojis to most of our transactions! It gets Beers (🍺), it gets when we speak English and write something like “Train” (🚂). But whenever we speak something in Portuguese or Italian, BAM, there comes the generic 💶 emoji.
Now. Is this a big problem? No. Is it an annoying problem? Yes. Is this a solved problem? Probably. But in the age of LLMs and 400 Billion parameters models, what options do we have?
Creating a labeled dataset from screenshots
Before looking at all the ways the Tricount emoji classification could be better, we should first gather a reasonable dataset. What before required some grueling hand labelling or some clunky OCR library, now ‘only’ requires a couple of calls to gpt-4o.
# Define data structure
class ExpenseItem(BaseModel):
name: str
amount: float
currency: str
payer: str
emoji: str
class Expenses(BaseModel):
expenses: List[ExpenseItem]
# Encode the images in base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
images_content = [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{encode_image(ima)}"},
}
for ima in pathlib.Path("../tricount_pictures").glob("*.PNG")
]
# Classify
response = client.beta.chat.completions.parse(
model=MODEL,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "List all the expenses in a json format",
},
*images_content,
],
},
],
temperature=0.0,
response_format=Expenses,
)
expenses = response.choices[0].message.parsed
# prints
#[ExpenseItem(name='Beers', amount=XXX, currency='DKK', payer='Dudu (me)', emoji='🍺'),
# ExpenseItem(name='Beers', amount=XXX, currency='DKK', payer='Dudu (me)', emoji='🍺'),
# ExpenseItem(name='Decatlon comun', amount=XXX, currency='DKK', payer='Vitto', emoji='💶'),
Just liked that, we now have a dataset of ~50 expenses. Great. Let’s get to classifying.
Classification using gpt-4o and structured outputs
Before we do anything else, how do the big guns perform? What if we just ask gpt-4o to classify? This is the simplest of options, even simpler now that OpenAI directly supports Pydantic base models via structured outputs. We can solve this problem in a couple dozen lines of code:
# define pydantic model
class EmojiClassification(BaseModel):
"""
A single emoji that describes a financial transaction (e.g., Airplane ticket -> ✈️)
"""
emoji: str = Field(
description="The emoji that describes the transaction (Must be a single character!)"
)
@field_validator("emoji")
@classmethod
def validate_emoji(cls, value):
if not emoji.is_emoji(value):
raise ValueError(f"The emoji must be a single character! Received: {value}")
return value
# classification function
def classify_openai(expense: str):
client = OpenAI()
messages = [
{
"role": "user",
"content": f"Classify this transaction: {expense}",
}
]
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini-2024-07-18",
messages=messages,
response_format=EmojiClassification,
)
return completion.choices[0].message.parsed.emoji
classify_openai("Treno Milano Ancona")
# prints '🚆'
That was easy. But also not particularly exciting. What if our data is sensitive? What if our API gets extremely popular? What if we just want to handle it ourselves? Could we do the same with some off-the-shelf open-source models?
Function calling local models with Ollama
I would love to tell you that open-source function calling was a solved problem. And yes - the function calling leaderboard certainly seems to tell that story. But the reality of local models is a bit different.
Here’s the code to accomplish the same thing OpenAI models can do with an Ollama model that supports function calling:
# Eats pydantic model, shoots 'json schema'
def schema(f) -> dict:
kw = {
n: (o.annotation, ... if o.default == Parameter.empty else o.default)
for n, o in inspect.signature(f).parameters.items()
}
s = create_model(f"Input for `{f.__name__}`", **kw).schema()
return {
"type": "function",
"function": {
"name": f.__name__,
"description": f.__doc__,
"parameters": s,
},
}
# Don't even try without this (email me if you have a better option!)
SYSTEM_PROMPT = """
You are a genius expert. Your task is to classify the description of a financial transaction with an emoji.
You must only use emojis that are a single character.
You must only reply with a single emoji.
Example 1:
User: Treno Milano Ancona
Response: EmojiClassification(emoji='🚆')
Example 2:
User: Dinner with friends
Response: EmojiClassification(emoji='🍽')
Example 3:
User: Plane ticket to New York
Response: EmojiClassification(emoji='✈️')
Use the EmojiClassification tool to help you classify the transactions.
""".strip()
# This is a bad example of retry logic - but you get the point
def classify_expense(
expense_description: str,
model: str,
retries: int = 3,
base_url: str,
api_key: str,
) -> EmojiClassification:
client = OpenAI(base_url=base_url, api_key=api_key)
classification_prompt = f"User: {expense_description}"
# poor man's retry
for retry_num in range(retries + 1):
# we use OpenAI's client
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": classification_prompt},
],
tools=[schema(EmojiClassification)],
temperature=0.0 + retry_num / 10,
)
tool_calls = getattr(response.choices[0].message, "tool_calls", None)
if not tool_calls or tool_calls[0].function.name != "EmojiClassification":
print(
f"Failed to classify expense. Expected EmojiClassification but got {tool_calls[0].function.name if tool_calls else 'None'}"
)
continue
try:
return EmojiClassification(
**json.loads(tool_calls[0].function.arguments)
).emoji
except ValidationError as e:
print(f"Validation error: {e}")
continue
return None
# we can now call this with ollama
classify_expense(
expense_description="Donut",
model="llama3.1",
base_url="http://localhost:11434/v1",
api_key="ollama", # dummy key - required
)
# prints '🍩'
Note: Using Instructor to accomplish the same
A kind user on twitter reached out mentioning you could do the same with Instructor I got a lot of Validation errors at the time, so I did not go this route, the code gets a lot simpler, so worth the test!def classify_expense(
expense_description: str,
model: str,
retries: int = 3,
base_url: str = "http://localhost:11434/v1",
api_key: str = "ollama",
) -> EmojiClassification:
client = instructor.from_openai(
OpenAI(
base_url=base_url,
api_key=api_key,
),
mode=instructor.Mode.TOOLS_STRICT,
)
classification_prompt = f"User: {expense_description}"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": classification_prompt},
],
response_model=EmojiClassification,
max_retries=retries,
)
return response
Perfect, we can now use any local Ollama model that supports function calling and classify our expense description as well.
Why don’t we try some old-school machine learning?
Embeddings for classification
Embeddings are another option. Open source, fast, and lightweight. Here’s a possible logic: given a list of emoji and their descriptions, as well as the description of an expense, return the ‘most similar’ emoji description to the expense.
Easier in code than in English:
# load a small db of emojis and descriptions
df = pandas.read_csv("./emojis.csv", index_col=False, header=None)
df.columns = ["emoji", "description"]
# prepare column to be embedded (I hate this)
df["description"] = df["description"].str.replace('"', "")
df["to_embed"] = "passage: " + df["description"]
# embed it (multilingual embedding, since the description are in IT and PT)
model = sentence_transformers.SentenceTransformer(
"intfloat/multilingual-e5-base"
)
embeddings = model.encode(df["to_embed"].tolist(), show_progress_bar=True, device="mps")
df = df.assign(vector=embeddings.tolist())
# create a lancedb table with the data
db = lancedb.connect(".my_db")
table_name = "emojis"
table = db.create_table(table_name, data=df.to_dict(orient="records"))
print(f"Created table {table_name}")
# Why not try a re-ranker as well?
ranker = Reranker("nreimers/mmarco-mMiniLMv2-L12-H384-v1")
# Create a classification function
def embedding_classify(
expense_description: str,
top_k: int = 10, # number of closest emoji to re-rank
use_reranker: bool = True,
debug: bool = False,
) -> str:
query_embedding = model.encode(
f"query: {expense_description}", show_progress_bar=True, device="mps"
)
r = table.search(query_embedding).limit(top_k).to_pandas()
if not use_reranker:
return r.iloc[0]["emoji"]
r = ranker.rank(
query=expense_description,
docs=r["description"].tolist(),
doc_ids=r["emoji"].tolist(),
)
return r.top_k(1)[-1].doc_id
print(embedding_classify("Beers and pizza with friends", use_reranker=False))
# prints 🍕
print(embedding_classify("Almoco", use_reranker=False))
# prints ⚗
Great, both the vanilla and re-ranked version of the function appear to work correctly. We now at least three ways of classifying the description of an expense.
Benchmarking expense categorization
We now have all the functions we need. With the code below, we now run a simple benchmark. For the 50 descriptions of expenses we gathered for our dataset, we run a set of different techniques/models.
I didn’t test all models in the world. I tested gpt-4o, 3-4 local models I usually run on my laptop, and the embedding techniques. Here’s the benchmarking code and results:
CACHE = {}
def benchmark(expense: ExpenseItem) -> dict:
if expense.name in CACHE:
return CACHE[expense.name]
result = {
"description": expense.name,
"tricount_emoji": expense.emoji,
"openai": classify_openai(expense.name),
"llama3.1_7b: ": classify_expense(
expense.name,
model="llama3.1",
**api_params,
),
"qwen2.5_3b": classify_expense(
expense.name,
model="qwen2.5:3b",
**api_params,
),
"qwen2.5_1.5b": classify_expense(
expense.name,
model="qwen2.5:3b",
**api_params,
),
"llama3.2_3b": classify_expense(
expense.name,
model="llama3.2",
**api_params,
),
"embedding": embedding_classify(expense.name, use_reranker=False),
"embedding_reranker": embedding_classify(expense.name, use_reranker=True),
}
CACHE[expense.name] = result
return result
results = [benchmark(expense) for expense in expenses.expenses[:30]]
bench_df = pandas.DataFrame(results)
bench_df
| description | tricount_emoji | openai | llama3.1_7b | qwen2.5_3b | qwen2.5_1.5b | llama3.2_3b | embedding | embedding_reranker |
|---|---|---|---|---|---|---|---|---|
| Beers | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍻 |
| Beers | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍺 | 🍻 |
| Decatlon comun | 💶 | 🛒 | 🏃 | 🛍 | 🛍 | None | 🌳 | 📨 |
| Duarte decatlon | 💶 | 🏃♂️ | 🏃 | 🛍 | 🛍 | 🏦 | 🌳 | 🌳 |
| Festa | 💶 | 🎉 | 🎉 | 🎉 | 🎉 | None | 🎭 | 🎑 |
| Jantar | 💶 | 🍽️ | None | 👩🍳 | 👩🍳 | 🏯 | ⚱ | ⚱ |
| Almoco | 💶 | 🍽️ | 🍏 | 🍔 | 🍔 | None | ⚗ | ⚗ |
| Jantar | 💶 | 🍽️ | None | 👩🍳 | 👩🍳 | 🏯 | ⚱ | ⚱ |
| Hotel Bolo | 🏨 | 🏨 | 🏨 | 🏨 | 🏨 | None | 🏨 | 🏚 |
| Treno Milano Ancona | 💶 | 🚆 | 🚂 | 🚆 | 🚆 | None | 🚄 | 🚡 |
| Cena vigana milano | 💶 | 🍽️ | 🍴 | None | None | None | 🌖 | 🌐 |
| Train venezia milano | 🚂 | 🚆 | 🚂 | 🚆 | 🚆 | 🚂 | 🚄 | 🚆 |
| Reimbursement | 💳 | 💸 | 💸 | ⛺ | ⛺ | None | 🚑 | 🎁 |
| Spritz | 💶 | 🍹 | 🍹 | None | None | None | 🥨 | ✨ |
| Mozzarella | 💶 | 🧀 | 🧀 | 🧀 | 🧀 | None | 🍝 | 🍄 |
| Spritz | 💶 | 🍹 | 🍹 | None | None | None | 🥨 | ✨ |
| Barca | 💶 | ⚽ | ⚽ | 🏀 | 🏀 | 🚣 | 🔖 | 📶 |
| Kwikly | 💶 | 🛒 | 💳 | 🏃 | 🏃 | None | 🥝 | 🥝 |
| Spesa | 💶 | 💳 | ✅ | 💰 | 💰 | None | ♠ | 🌾 |
| Voli Tokyo | 💶 | ✈️ | 💖 | ✈️ | ✈️ | ✂ | 🗼 | 🗼 |
| Conguaglio voli Zurigo | 💶 | ✈️ | ✈️ | ✈️ | ✈️ | ✈ | 🔄 | 🌐 |
| Amar | 💶 | 👤 | 💸 | None | None | 🤑 | 🕉 | 💢 |
| Groceries | 🛒 | 🛒 | 🛍 | None | None | 🛍 | 🥫 | 🍲 |
| Durum | 💶 | 🍞 | 🥖 | 🍞 | None | 📦 | 🥁 | 🛢 |
| Groceries | 🛒 | 🛒 | 🛍 | None | None | 🛍 | 🥫 | 🍲 |
| Money transfer | 💳 | 💸 | 💸 | 💸 | 💸 | None | 💰 | 🤑 |
| Lunch | 🍜 | 🍔 | 🍏 | None | None | 🍽 | 🥪 | 🕐 |
| Cafe | 💶 | ☕ | ☕ | ☕ | ☕ | ☕ | ☕ | 🔪 |
| Spesa kwikly | 💶 | 🛒 | ✅ | 🛒 | 🛒 | None | 🐳 | 💪 |
| Pizza | 🍕 | 🍕 | 🍕 | 🍕 | 🍕 | None | 🍕 | 🍕 |
Note: None means the model did not call the appropriate function, and thus failed to produce a classification.
Closing thoughts
Looking at the results, we can observe a couple of interesting things:
OpenAI’s gpt4-o is hard to beat. It pretty much never missed. Even when Vitto was too lazy to write the rest of the description. My guilty pleasure shopping at decathlon? Got it. Barca was actually referring to boat - and not the actual football club - there’s no way it could’ve figured that one out. Hard to beat. Kwikly refers to a local supermarket we go to in Copenhagen - and that looks like a store emoji to me!
The bigger the open model, the better the results. And Llama 3 shows it. It performs pretty well, especially at the 7b size. Not without hiccups, of course (can’t figure out how 💖 relates to flights?).
Small open source models are getting good. Not sure what happened to Llama 3.2 3b - but at 3 and 1.5b sizes, Alibaba’s Qwen2 family of models perform surprisingly well. Some bigger problems do show up. We also see a lot of failures to call the right function. (hence the Nones). I’m still curious about two things. (1) How much better could we get through prompting. (2) How much better larger open source models perform (think 70B or 400B). I can’t run those myself, so it’s beside the point of this post.
The embedding idea sounded interesting, but didn’t really perform. We would probably have to do a bit more work than just a cosine similarity on the emoji descriptions. Even though the embeddings were multilingual, they clearly didn’t capture the essence of the expense. Another approach I would test is to create a labeled dataset with gpt-4o and then a simple random forest on embeddings. But again, beside the point of this post.
In any case, we can for sure do better than what Tricount is currently doing!
Epilogue: Just get the right token
Sorry, I couldn’t resist. I need to test a last one. OpenAI has a cool feature called log probs in their API that allows you to run classification by querying by which token has the highest probability in the completion.
Unfortunately, Ollama doesn’t seem to support this. But I figured how to do with plain Transformers. Not the most efficient, since I have to run for every possible emoji. But do let me know if you (reader) have better suggestions:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-3.2-1B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# log probability of sentence
def calculate_sentence_log_probability(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits[:, :-1, :] # Align token predictions
shifted_input_ids = inputs.input_ids[:, 1:] # Drop first token
log_probs = torch.log_softmax(logits, dim=-1)
token_log_probs = log_probs.gather(2, shifted_input_ids.unsqueeze(-1)).squeeze(-1)
return token_log_probs.sum().item()
# wrapper to run through the emojis
def find_most_likely_emoji(base_sentence, emoji_list):
log_probs = {}
for emoji in emoji_list:
sentence = base_sentence.format(emoji=emoji)
log_probs[emoji] = calculate_sentence_log_probability(sentence)
most_likely_emoji = max(log_probs, key=log_probs.get)
return most_likely_emoji, log_probs
# prompt
USER_MESSAGE = """
You are a genius expert. Your task is to classify the description of a financial transaction with an emoji.
You must only use emojis that are a single character.
You must only reply with a single emoji.
Example 1:
User: Treno Milano Ancona
Response: 🚆
...
Now it's your turn! Classify the following transactions with an emoji:
User: {description}
""".strip()
USER_MESSAGE = USER_MESSAGE.format(description="Voli Tokyo") # 'Flights Tokyo'
# massaging the formats and tokenizing
ASSISTANT_MESSAGE = """Response: {emoji}"""
chat = [
{"role": "user", "content": USER_MESSAGE},
{"role": "assistant", "content": ASSISTANT_MESSAGE},
]
input_tokens = tokenizer.apply_chat_template(chat, tokenize=True)[:-1]
base_sentence = tokenizer.decode(input_tokens)
# classification
emoji_list = ["🎄", "🔔", "🚨", "💎", "🇬🇹", "🍹", "🚣", "⚽", "🥘", "🛩️", "🇯🇵", "✈️"] # example possibilities
most_likely_emoji, log_probs = find_most_likely_emoji(base_sentence, emoji_list)
print(f"Most likely emoji: {most_likely_emoji}")
for emoji, log_prob in log_probs.items():
print(f"Log probability of {emoji}: {log_prob}")
# Most likely emoji: ✈️
# Log probability of 🎄: -582.9215087890625
# Log probability of 🔔: -580.827392578125
# Log probability of 🚨: -577.4615478515625
# Log probability of 💎: -582.4413452148438
# Log probability of 🇬🇹: -580.4923095703125
# Log probability of 🍹: -581.0596923828125
Works well!