TTS doesn't suck anymore
About 6 months ago I wrote a small rant on how open source TTS models still sucked. 6 months later, I'm happy to report that isn't the case anymore.
January this year, Qwen, the famous Chinese AI lab, released Qwen3-TTS, an open-weights series of TTS models. The release included 2 CustomVoice models (pre-made voices + style control), 2 base models (zero-shot voice cloning + fine-tuning), and a VoiceDesign model (create voices from descriptions). With a 0.6B and a 1.7B variant - they're all quite small.
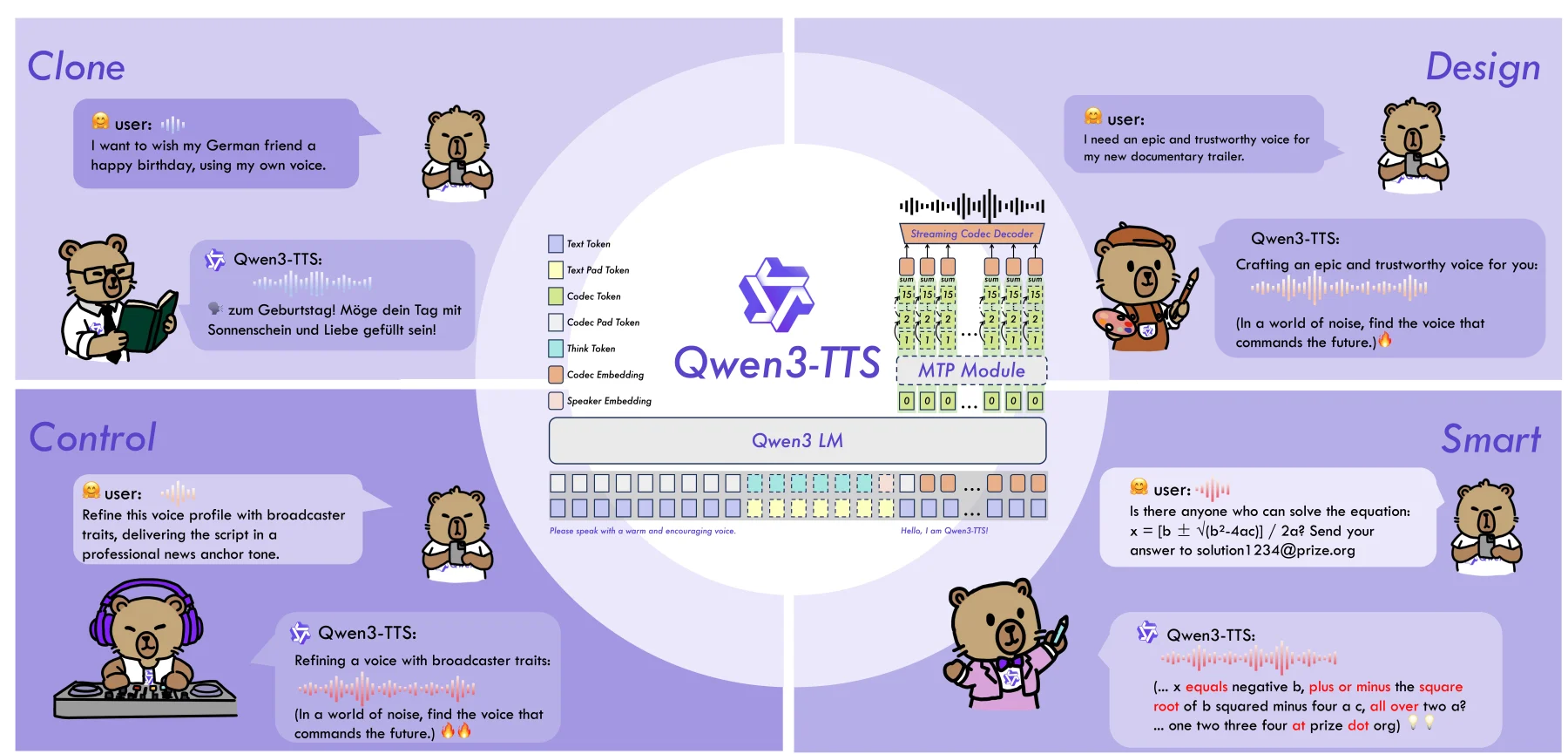
There are a lot of things to like. First, it fully supports voice cloning - via fine-tuning or zero-shot conditioning. Voxtral, for example, doesn't. Second: the license is Apache 2.0 - which means we can do whatever we want with it (beware). Third, it's supported by a strong inference engine. In this case vLLM-Omni. And more importantly: it avoids many of the small issues other open-source TTS models had when generating longer pieces of text — squeaks, audio drops, weird pacing, etc.
There are some caveats. There is a small bug on the fine-tuning code which creates some weird accelerations. The base models don't support "style-guidance" - e.g., you can't tell your fine-tuned model to sound very angry - or very sad.
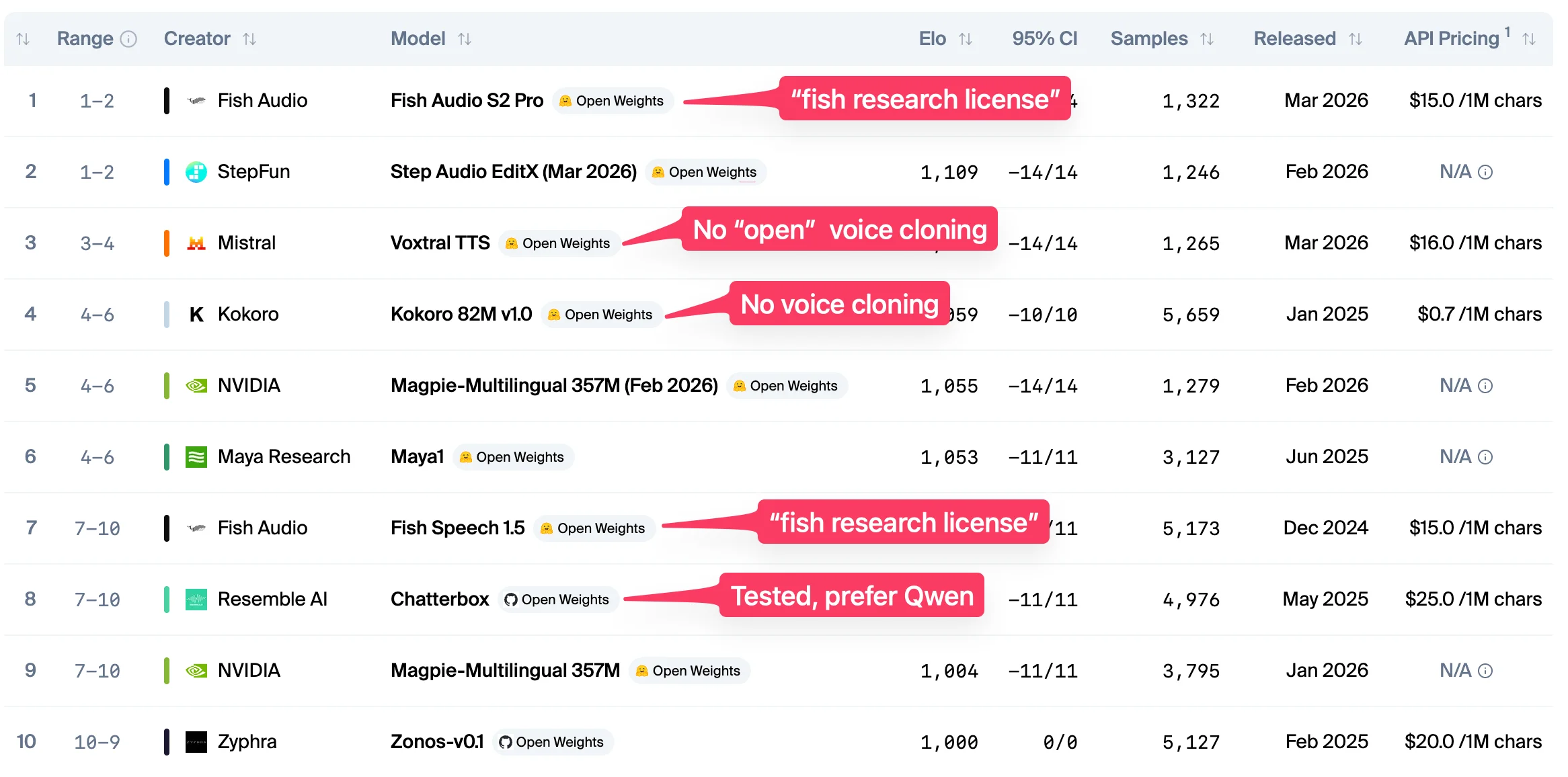
For some reason, it's not on the Speech Arena leaderboard for Open Weights models. There are two entries in the ranking - not sure what model they refer to. But from my experience, it's not all about the model. The inference around it and how it "behaves in the wild" is what matters most and Qwen3-TTS delivers.
I spent a morning getting a dataset ready for fine-tuning by reading a couple of articles out loud, and generating training samples with MacWhisper and Parakeet. I tweaked some of the fine-tuning code to avoid the acceleration bug, and trained a 0.6B base model on a Scaleway H100. I updated my podcaster package so that it runs the fine-tuned model on Modal. Instead of running on scheduled GitHub actions (we all know how those go) - it now runs fully on my Coolify instance.
Here's an example article transcription with the old vs. the new model:
Chatterbox (original - not the new ones)
Qwen3-TTS 0.6B fine-tune - 200 samples, 6 epochs - Hugging Face 1
TTS is moving fast. There are a lot of things I haven't tested yet. OmniVoice is one of them, StepFun's Step-Audio-EditX is another.
But the main takeaway is that TTS doesn't suck anymore. We have options now.
- I trained on only 30 minutes of audio - I should add a lot more in the future to make the audio even better. Might sound a bit less like me - but certainly cleaner to listener's ear imo. I might upgrade to the 1.7B model to make it even better. ↩