Serving models with FastAPI: It's not just about the speed
Disclaimer: This post was originally published in the Amplemarket blog
Serving and deploying Machine Learning models is a topic that can get complicated quite fast. At Amplemarket, my team and I, like to keep things simple.
Let's talk about it.
Simplicity is key
At Amplemarket, we’re big fans of simplifying. We know that the less code we have to write, the fewer bugs we're likely to introduce. FastAPI allows us to take a trained model and create an API for it, in less than 10 lines of code! That’s pretty incredible.
Let’s say you are creating a model that is trained on the Iris data set that predicts the species of a plant given some information about it. Previously, we would have saved our model to a pickle file, and sent it to our engineering team; perhaps we would have even scheduled a meeting with them to discuss how to use this model. We would also have sent some documentation on how to use that model and how it can inference on some data.
But the likelihood that something will go wrong in one of those steps is greater than we’d like. Every time the model gets updated, we would need to have another discussion, about how the model has changed, and what gets improved - documentation would get outdated, etc.
To avoid dealing with that house of cards, we at Amplemarket have settled on a process that significantly reduces the complexity of deploying the machine learning models we develop.
As an example, the following snippet trains a classifier and saves it to the model.joblib file:
Note: To run the snippets, make sure to python -m pip install scikit-learn fastapi "uvicorn[standard]"
from sklearn import svm
from sklearn import datasets
import joblib
# create model
clf = svm.SVC(probability=true)
X, y = datasets.load_iris(return_X_y=True)
clf.fit(X, y)
# save model
joblib.dump(clf, 'model.joblib')
With FastAPI, serving your model is as simple as creating an app.py file with the following contents:
# app.py
from typing import Optional
from fastapi import FastAPI
import joblib
# create FastAPI app and load model
app = FastAPI()
model = joblib.load("model.joblib")
# create an endpoint that receives POST requests
# and returns predictions
@app.post("/predict/")
def predict(features):
predictions = model.predict([eval(features)]).tolist()
return predictions
You can then launch the API with uvicorn app:app --reload.
Such a simple setup to launch an API ensures that our Machine Learning team is not limited to creating these models, but also responsible for making them available to our development team, or even directly to our users.
“You built it? You ship it”
Reduce the need for coordination
As a remote, distributed, and asynchronous team, documentation is huge for us. We don’t want to have a meeting with 5 other departments every time we build or ship a new model. We want to document as best we can, with the least effort possible.
With the script described above, if you visit localhost:8000/docs you’ll notice that your API includes some documentation out of the box:
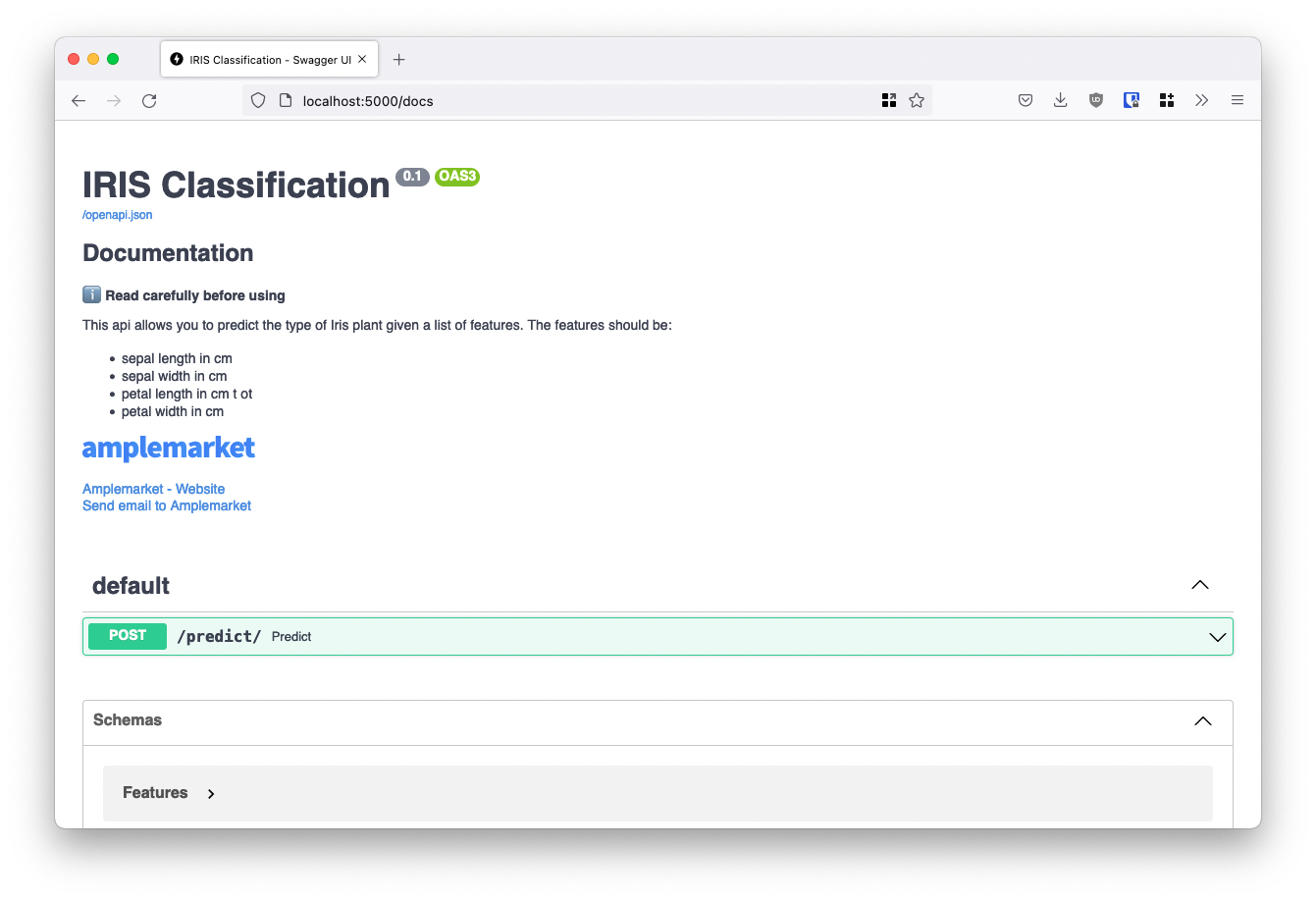
These docs already tell a lot about the application: what endpoints it has, what type of queries the user can send, etc. We love FastAPI because it takes little work to enrich the documentation further and minimize the need for future coordination.
Let’s add a couple of things to our app.py script:
from fastapi import FastAPI
import joblib
# some documentation in markdown
description = """
## Documentation
**ℹ️ Read carefully before using**
This api allows you to predict the type of Iris plant given a list of features.
The features should be:
* sepal length in cm
* sepal width in cm
* petal length in cm
* petal width in cm
_Build by:_

"""
# create FastAPI app and load model
app = FastAPI(
title="IRIS Classification",
description=description,
version="0.1",
contact={
"name": "Amplemarket",
"url": "<https://amplemarket.com>",
"email": "[email protected]",
},
)
# ... rest of the file ....
If we now turn back to our docs, we see that the markdown we've added has been rendered at the top of the page. Now, when someone needs to check some details about this model, all the information that person might need is neatly described - and we even provide a support email if they run into trouble!
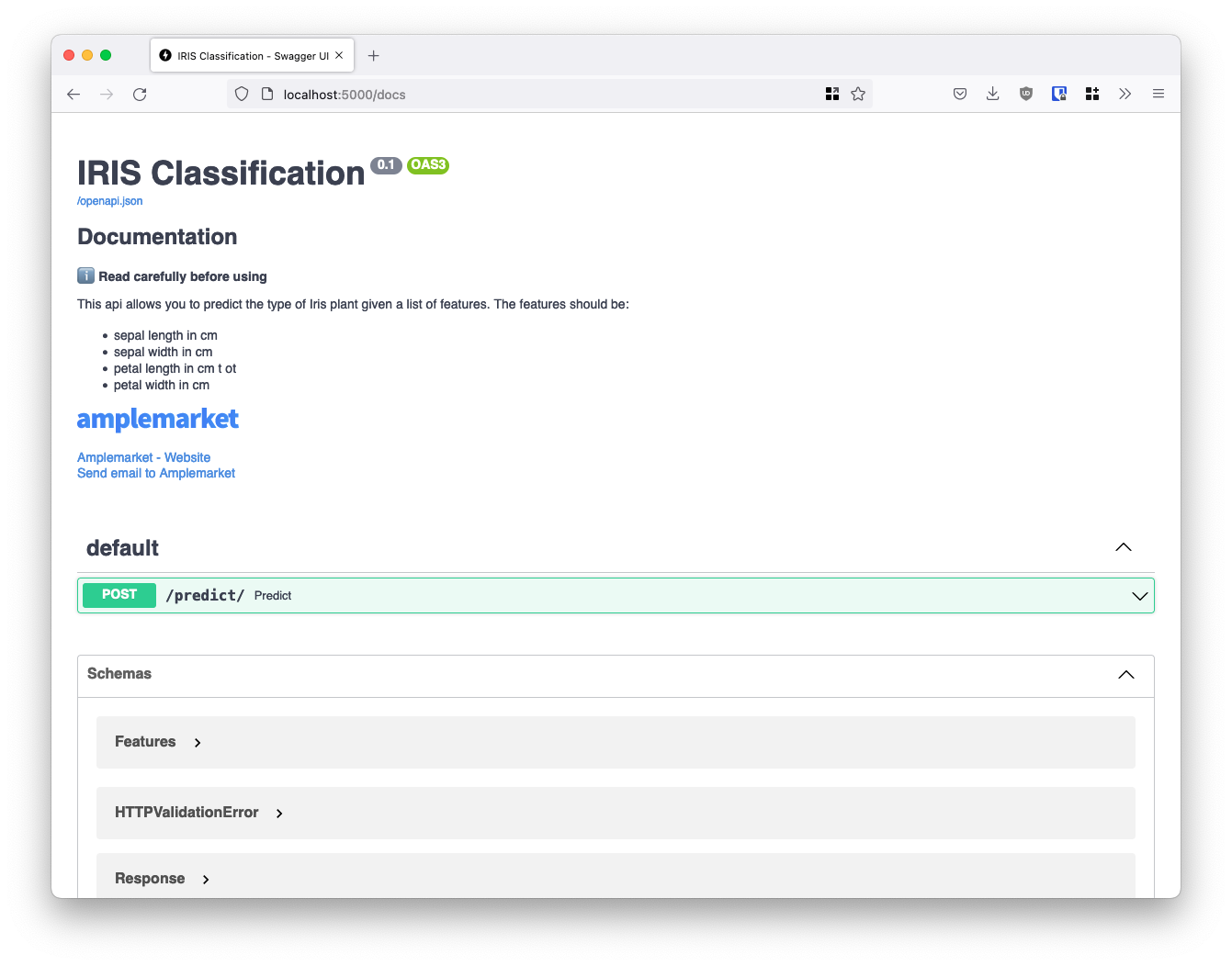
But FastAPI doesn’t stop there.
With a couple more lines of code, and thanks to a small library called Pydantic, we can also add data validation to our model’s API. By doing so, API users will know what kind of data it expects to receive and what kind of data the API will respond back with.
We start by creating two classes, one to handle requests, and the other for responses:
# We'll take this in:
class Features(BaseModel):
sepal_length: confloat(ge=0.0, le=1.0) # ensures values are between 0 and 1
sepal_width: confloat(ge=0.0, le=1.0)
petal_length: confloat(ge=0.0, le=1.0)
petal_width: confloat(ge=0.0, le=1.0)
# with an example
class Config:
schema_extra = {
"example": {
"sepal_length": 0.2,
"sepal_width": 0.5,
"petal_length": 0.8,
"petal_width": 1.0,
}
}
# We'll respond something like this:
class Response(BaseModel):
setosa_probability: confloat(ge=0.0, le=1.0)
versicolor_probability: confloat(ge=0.0, le=1.0)
virginica_probability: confloat(ge=0.0, le=1.0)
# with an example
class Config:
schema_extra = {
"example": {
"setosa_probability": 0.7,
"versicolor_probability": 0.1,
"virginica_probability": 0.2,
}
}
And we tweak our endpoint code:
# the endpoint
@app.post("/predict/", response_model=Response)
def predict(features: Features):
feature_list = [
features.sepal_length,
features.sepal_width,
features.petal_length,
features.sepal_width,
]
predictions = model.predict_proba([feature_list])[-1]
predictions_clean = Response(
setosa_probability=predictions[0],
versicolor_probability=predictions[1],
virginica_probability=predictions[2],
)
return predictions_clean
The two classes above are particularly strict about what our API can receive and what it will respond back with. Suppose a developer tries to query the API with a petal_width of 1.3. Because we’ve specified that petal width must be a number between 0.0 and 1.1, our API will reject the query and reply back with:
## request
curl -X 'POST' \\
'<http://localhost:8000/predict/>' \\
-H 'accept: application/json' \\
-H 'Content-Type: application/json' \\
-d '{
"sepal_length": 0.2,
"sepal_width": 0.5,
"petal_length": 0.8,
"petal_width": 1.1
}'
## response
{
"detail": [
{
"loc": [
"body",
"petal_width"
],
"msg": "ensure this value is less than or equal to 1.0",
"type": "value_error.number.not_le",
"ctx": {
"limit_value": 1
}
}
]
}
As an added bonus, the model Config classes also help provide developers with an example request and response:
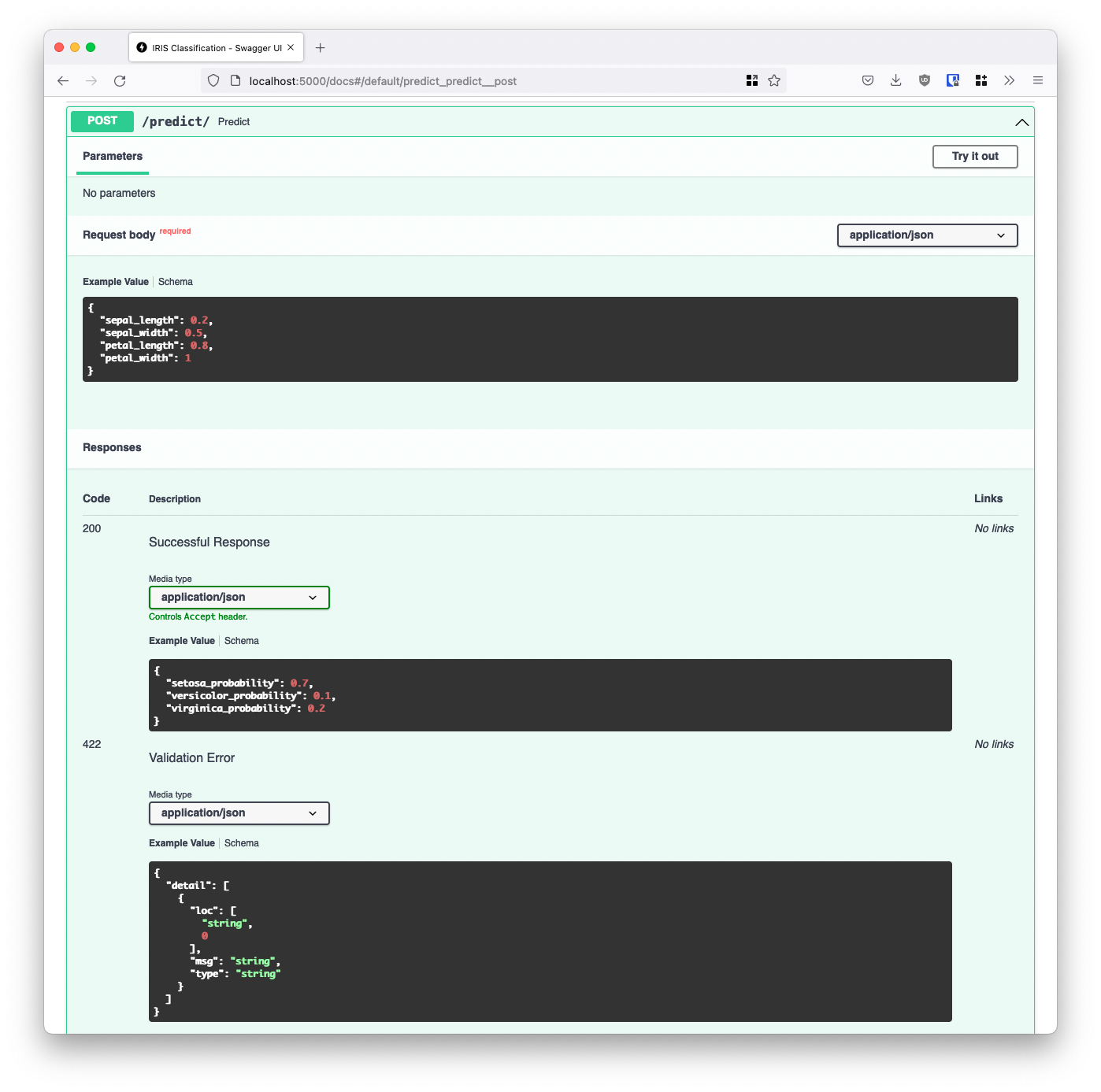
With this documentation page at hand, our users know exactly what our API is, what it expects, and what it will reply back.
All of this comes without us having to invest much time and effort into ensuring the documentation has all the information that future developers might need. And notice how we didn’t have to write any extra documentation.
Our documentation is our code.
Make it fast (enough)
Python is far from the fastest language out there, nor does it claim to be. We don’t use Python for its speed, but for its ecosystem, especially as it relates to data science and its many needs.
Even with several claims that FastAPI is a very performant web framework, we know we’re not using the fastest web framework out there.
However, even if FastAPI was slower than it currently is, we would still be willing to compromise that speed for time-to-market, documentation, and ease of use.
When deploying, Sebastián Ramírez offers a FastAPI/uvicorn high-performance docker image with auto-tuning. Allowing the app to scale according to the number of available CPU cores on the machine it's running on:
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app
If you’re running on Kubernetes or something like that, you probably don’t need this image - but if you have a simpler setup, this image will come very in handy!
Deploy with confidence
At Amplemarket we like to adopt best practices from Software Development and apply them to our Machine Learning projects. That means every model we develop and deploy is version controlled, tested, and continuously deployed.
Using CI/CD automation, we can continuously deploy our model and code to several targets (e.g., staging and production). Allowing us to serve different versions of our model in different endpoints, and roll back with ease.
FastAPI also allows us to easily test our code. This is especially important when we are inferencing. What if we receive a different set of numbers? Will we make a prediction? What if the user sends us a string, and it gets evaluated as a float? How do we account for that? Testing matters. And FastAPI allows us to do it with ease.
Closing thoughts
FastAPI has been particularly valuable when serving our Machine Learning models. Our development team is especially happy with the high level of documentation and data validation that our APIs offer and our users also get those benefits.
Thanks to FastAPI, we’ve been able to predict with confidence, and I hope you got some inspiration from this post to gain confidence as well.
Note: This is also a show of appreciation to the incredible work of FastAPI’s lead developer Sebastián Ramírez.