parlabot - ask the Portuguese parliament
Large language models (LLM) are really dumb. I mean, how can you fail when the question is as simple as "What is 23 times 18"? Even though they're making most headlines, at the end of the day, these models are, predicting the next token based on the previous ones. If we ask a super simple question without any context to an LLM, the performance will only depend on how much the model has seen that example.
But LLMs are also amazing. Have you used GitHub copilot lately? I don't trust it to write my functions for me, but damn it writes a good boilerplate. It's like auto-complete, but better. It doesn't only know your imports. It knows where you are in the code base, and can suggest based on that.
The difference? Context. When using copilot, your code is the context, and that's why copilot knows exactly what to suggest. So how can I give the right context to one of these models? To answer this, I built parlabot. Parlabot (parlamento + bot) uses all transcripts from the Portuguese parliament to answer any question you might have about Portuguese politics. It also (tries) to do so in the most truthful way it can, with the information it has.
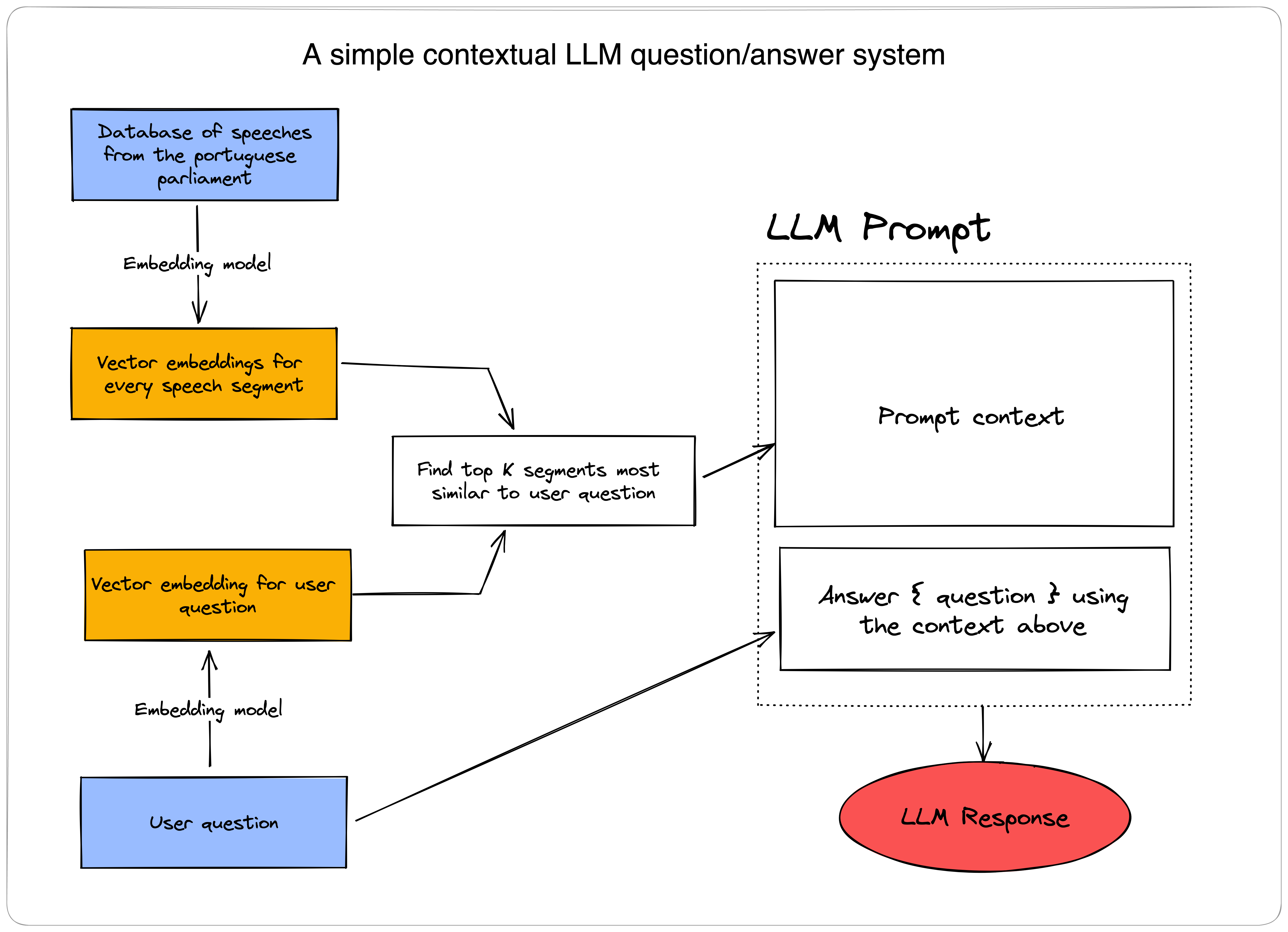
There are two things at play when you ask a question to parlabot. Below is a sketch that might make things easier to follow.
The first part is the search engine. To make this work, I scrapped all transcripts from the Portuguese parliament and used a multilingual embedding model to transform them into vectors. Whenever you type in a question, I embed it using the same exact model, transforming it into another vector. I then find the top k most similar reference vectors to the query vector. This is the same as finding the top K most relevant speech segments for that question.
Once I have the most relevant speech segments, it's time to build the prompt. The prompt, has two parts, the context, and the direction. The context, is simply the most relevant speech segments, the corresponding speakers, and the political parties. In the direction part of the prompt, I ask GPT3 to answer a given question using the segments from the context.
The results are pretty good! The bot is very capable of using the context given to answer most questions. Of course, the context is not always relevant to a question. For example, if you ask "How to bake a cake?", it's unlikely we'll find the answer in the data set of parliament transcriptions. With good prompt design, we can make the bot answer "I don't know" when this is the case.
The mix of LLMs, politics, and poorly written code is a great recipe for disaster. Although disaster does sound pretty fun, I don't expect this bot to answer truthfully any of the questions Portuguese tax-payers have about elected parties. These answers should be taken with a massive grain of salt and skepticism. LLMs are stochastic beasts that might predict two different outputs with the exact same set of inputs.
Still, this system might be interesting to solve problems where the cost of failure is not catastrophic. Without forgetting, that a bit of skepticism is a great foundation for any ML system.