An opinionated Python boilerplate
There's nothing quite like starting a new project. A greenfield, filled with possibilities. It's a privilege many don't come across. A lot of us, get thrown into projects with a lot of legacy code. But sometimes, we start from scratch.
This is the time. The time to make all the right calls. The time to use the right tools, the right abstractions, and the right structure. The unfortunate truth is, there is no right way. There are just ways. Most of us use the tools we're comfortable with. We've tried things in the past. Some worked, some didn't.
I've started my fair share of Python projects. By failing, a lot, I've converged to a set of tools. These will change over time. But in the hope to help a fellow Pythonista out there, let's talk about them.
Pip-tools for dependency management
Now I don't want to start a packaging war. If Poetry works for you, then by all means, go for it. I've tried most of the stuff out there, from the good old pip freeze > requirements.txt, pipenv, all the way to Poetry. After many battles, I've stuck with pip-tools. Pip-tools strikes the right balance between simplicity, effectiveness, and speed. And yes, speed matters. I don't want to wait a whole minute for my dependencies to compile.
With recent pip updates, I can just specify my dependencies in a pyproject.toml and install them with pip install -e .. However, there are benefits to pinning your dependencies using something like pip-tools. Especially in Machine Learning environments. Yes Anaconda exists - but speed is a requirement.
The folks at Jazzband have created an easy-to-use tool that has yet to let me down. For example, suppose I have a dreambox project. Here's an example pyproject.toml file:
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project]
name = "dreambox"
version = "42"
dependencies = ["pandas>=1.5.3", "numpy", "fastapi"]
[project.optional-dependencies]
dev = ["pytest"]
To create a pinned and hashed requirements file , all you need to do is:
(env) $ pip-compile --generate-hashes --output-file=requirements.txt pyproject.toml
(env) $ pip-compile --generate-hashes --extra=dev --output-file=requirements-dev.txt pyproject.toml
That ensures whatever you build in production is reproducible in my own machine, to the exact dependency and hash.
Pyproject.toml for configuration
Who likes configuration files? I certainly don't. There's nothing nice about having 15 configuration files at the root of my project. One for test coverage, one for linting, one for GitHub, one for formatting, and another one for CI. No thanks.
Fortunately, PEP 621 happened. And with it, a (mostly) common way to store all of the metadata and configuration for a Python project. Using a single pyproject.toml, I can define my local package name and details, my pinned dependencies, my pytest coverage configuration, my formatting configuration, my... You get me. All the configurations, in a single file. Expand the example below for an example.
An example pyproject.toml
# packaging information
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
# project information
[project]
name = "dreambox"
version = "23.1.26"
readme = "README.md"
requires-python = ">=3.10"
# requirements.txt generated from here
dependencies = [
"Jinja2>=3.1.2",
"loguru>=0.6.0",
"fastapi>=0.88.0",
"uvicorn>=0.20.0",
]
# requirements-dev.txt generated from here
[project.optional-dependencies]
dev = [
"black>=22.10.0",
"isort>=5.10.1",
"pip-tools>=6.10.0",
"pytest>=7.2.0",
"pytest-cov>=4.0.0",
]
# linting config
[tool.ruff]
ignore = ["E501"]
# isort config
[tool.isort]
profile = "black"
line_length = 79
skip = [".env/", "venv", ".venv"]
# coverage config
[tool.coverage.paths]
source = ["src"]
[tool.coverage.run]
branch = true
relative_files = true
[tool.coverage.report]
show_missing = true
fail_under = 80
# formatting config
[tool.black]
line-length = 79
extend-exclude = '''
/(
| .env
| .venv
| venv
| notebooks
)/
'''
Makefiles for common sense
I clone a new repo. Now, where the hell do I start? How do I run the tests? How do I run the API? There should be a common standard for these things right? Wrong. Every project is different. Every project has its pet peeves. I don't really like pet peeves. Anyone should be able to pick up my project and get up and running straight away. No meetings, no calls, just start working. A well-documented README.MD might work. But you'll get lazy.
So what is the easiest way to add a good project "map", without much work? Enter my Makefile. With a Makefile, I define all of the main project commands in a single file. For example:
## Install for production
install:
python -m pip install --upgrade pip
python -m pip install -e .
## Install for development
install-dev: install
python -m pip install -e ".[dev]"
## Build dependencies
build:
pip-compile --resolver=backtracking --output-file=requirements.txt pyproject.toml
pip-compile --resolver=backtracking --extra=dev --output-file=requirements-dev.txt pyproject.toml
If I want to install the dependencies on a project, all I do is make install. Or make install-dev for the dev dependencies as well. This is nice. But my favorite feature is this:
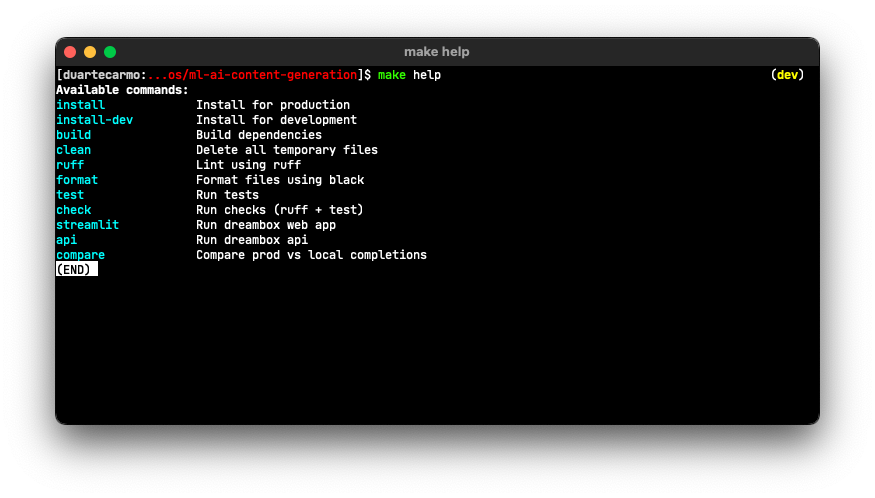
make help, and they'll get a good idea of how to navigate things. The script takes the comment above every rule in the Makefile, so it's super easy to add new commands to it.
Now isn't that nice?
Ruff for linting
I like Python, but I also like Rust a lot. Ruff is a new (and shiny) Python linter written in Rust. It's probably the most modern project in my boilerplate. It does what any linter should do, it should flag errors and bad practices. I like catching errors before they blow up in the user's face.
Most importantly, Ruff is fast. Blazingly fast one might say? Running ruff in our project will probably take less than half a second. Also, like all other tools I mentioned here, Ruff supports pyproject.toml for configuration. So you don't have to have to maintain yet another file. (I'm looking at you flake8)
Black & isort for formatting
I never got the whole tabs vs. spaces thing. But I do know programmers have opinions. So many opinions. A cool thing about working in software is that you can use software to squash those opinions. We just agree on using a couple of tools to format our code, all other discussions become useless. So thanks, Łukasz, for creating Black.
Most of my projects have a great make format rule, that runs black and isort. The configuration? It's in my pyproject.toml file above.
## Format files using black
format:
isort .
black .
Note: Apparently ruff supports import sorting now? Wow. My boilerplate is already obsolete.
pre-commit hooks (I don't)
I've seen a lot of projects adopt pre-commit hooks as a way of enforcing standards for code. Whether it's to make sure tests pass or to ensure nothing gets raised by linters, pre-commit hooks are all the rage. The thing is, git is already pretty complicated. I mostly work with data scientists, and most of them already face a steep curve in adopting software practices. From my (opinionated) experience, pre-commit hooks make things even more complicated.
But yes, some standards should be enforced, otherwise, something will break for sure. But isn't that what CI is for? Enforcing something like formatting and linting is easy with the --check flag:
## Run checks (ruff + test)
check:
ruff .
isort --check .
black --check .
If I run make check and something doesn't comply, I'll get an error. When opening a PR with a new feature, CI can take care of all of those checks:
on:
pull_request:
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Install dev requirements
run: make install-dev
- name: Check formatting # <- if this does not pass
run: make check
- name: Run tests # <- you don't get here
run: make test
If something doesn't run, CI doesn't pass. No need to mess around with git in everyone's machine. Everyone is free to commit whatever they want - and will get notified if something is not working. That's good enough.
An example project
At some of my previous talks, people normally ask me to share my project template (e.g., my cookiecutter). For me, sharing project templates it's a bit like copying someone else's Vim config. As soon as you need to tweak something (and trust me, you will), you'll have a headache.
This boilerplate is made of choices (or traumas) I've experienced over time. It's tailored exactly to my needs (e.g., data science, machine learning, API design). I like simple things a lot.
I do think it could serve some as a starting point for their own opinionated boilerplate. So here's the code, fellow Pythonista. Have fun out there.
Updates & notes
- This post was featured in Episode #326 of the PythonBytes podcast