AMÁLIA and the future of European Portuguese LLMs

Update July 2026: The AMÁLIA models have now been released! You can find the weights/datasets on Hugging Face. Some parts of this blog post might be out of date. So beware!
In December 2024, the Portuguese government announced AMÁLIA: a 5.5 Million Euro investment on a large-scale LLM for European Portuguese1.
The other day, while building an overview of the different Portuguese NLP efforts, I stumbled upon the technical report! I couldn't believe my eyes. Much to talk about! Let's get straight to it!
Actually, before we do. A quick disclaimer: AMÁLIA is an impressive piece of work. And the researchers should be very proud. But when the investment from the state is this significant, the entire country is the recipient of the work - and so I think it's only fair to ask some hard questions. If you participated on the project and are reading this: Thank you for your work!
Alright - now let's get to it.
AMÁLIA in a nutshell
AMÁLIA is "a fully open source Large Language Model (LLM) for European Portuguese". The goal is simple: to create an LLM that treats European Portuguese as a first-class citizen. Italy, for example - did something similar with Minerva. AMÁLIA is a result of a collaboration between several top tier Portuguese Universities and Research Labs (NOVA, IST, IT, and FCT).
Contrary to what I would have expected, AMÁLIA is not trained from scratch. It's a continuation of the pre-training phase of EuroLLM: an earlier effort (with a lot of Portuguese manpower!). To my understanding, the architecture is the same as EuroLLM, with some slight modifications to the context length and RoPE scaling.
Now, how does AMÁLIA focus on Portuguese? One word: Data. Across every different training stage they tried to increase the share of European Portuguese data the model was trained on. During pre-training they used Arquivo.pt data, during supervised fine tuning (SFT) they synthetically generated Portuguese data, and during preference training they sub-sampled some of the data from the SFT phase.
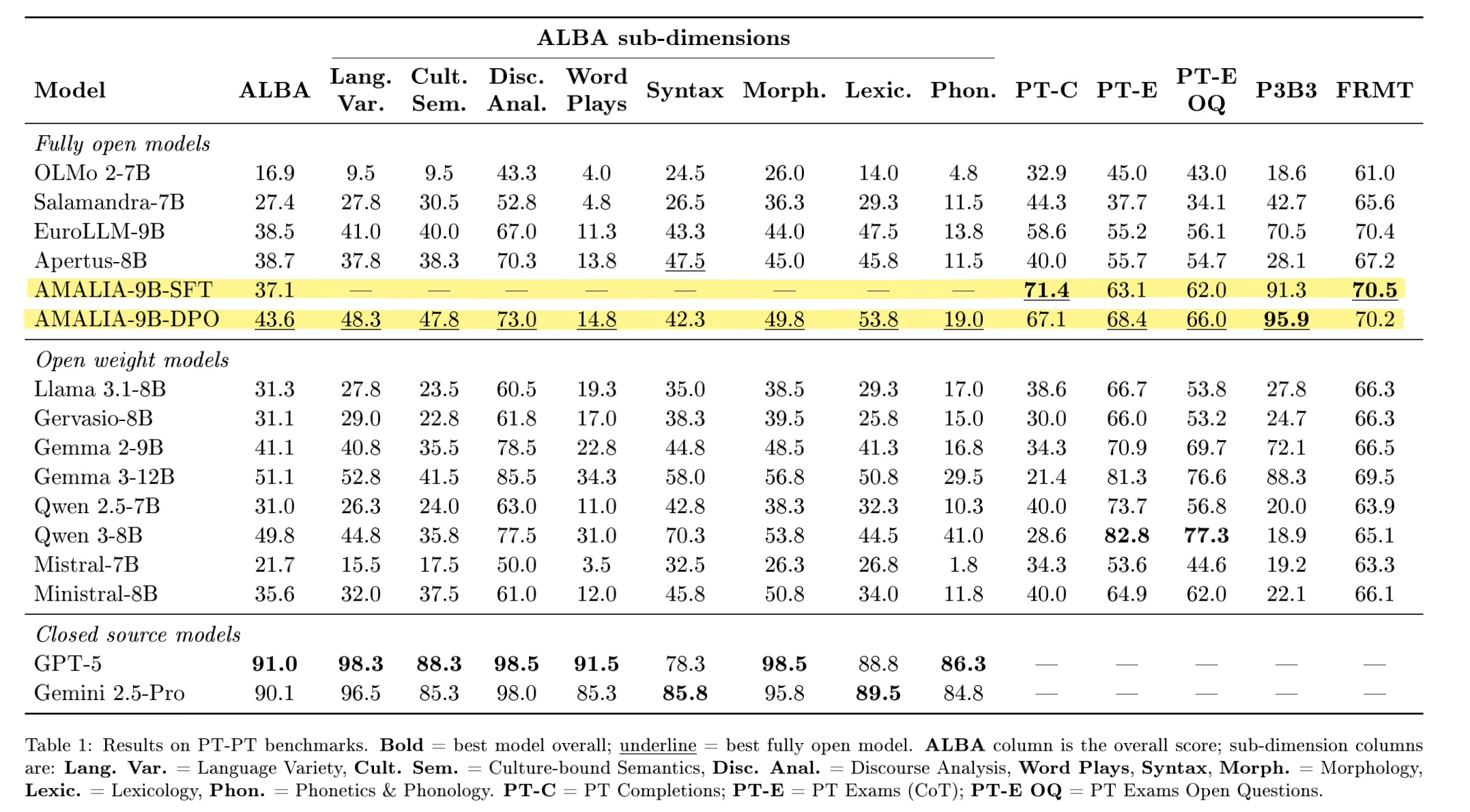
Training is interesting and all, but even more interesting is to measure if what was trained was any good. Which for this particular case, can be especially challenging. The team created four new benchmarks specific for European Portuguese. The most prominent one of these is ALBA.
How open source, really?
The standard for fully open models is Olmo. Olmo doesn't lead benchmarks. That's not the point. The point of Olmo is to be extremely open. Just browse their technical report. Weights? Open. Data? Open. Code? Open. Training logs? Open. Everything is publicly accessible. Which makes it an incredible resource.
At the moment I'm writing this, very little of AMÁLIA is open. I could not find the model weights, data, training logs, or new benchmarks listed anywhere. The Arquivo.pt processing scripts are open, but the resulting dataset itself is nowhere to be found. For now we have some GitHub repos. In the era of many "open weights" but few "open source" LLMs, it has never been more important to put these things out there, and put them out there fast.
Maybe it's a matter of time. Maybe there's something beyond my understanding as to why we still have no model weights. Maybe it's a research-in-progress.
But even if they released weights tomorrow, I'm not sure I'm completely sold on the approach.
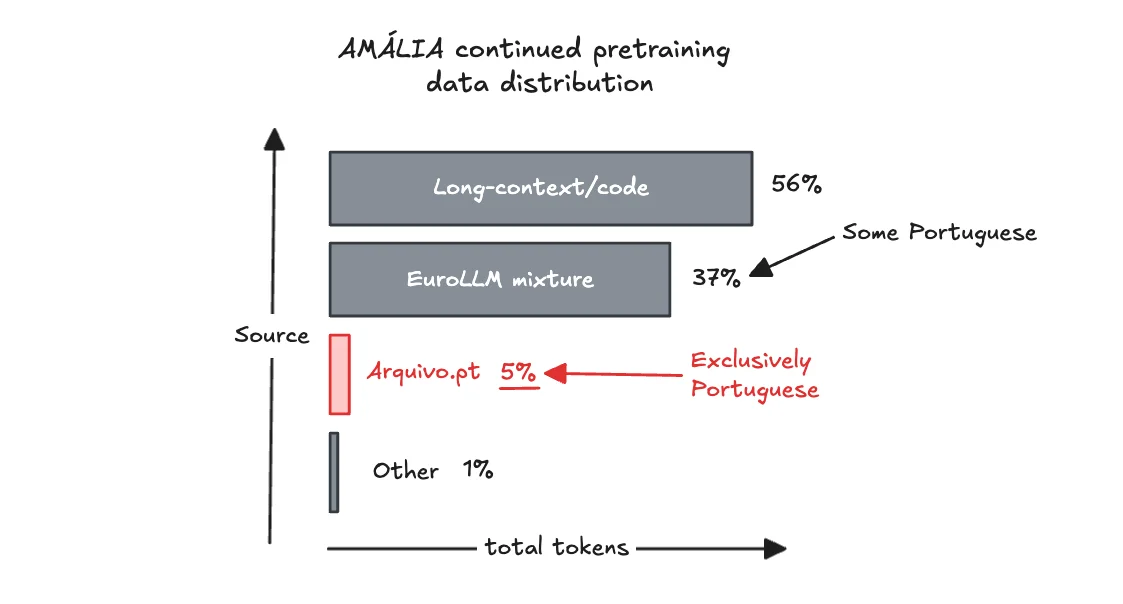
How much Portuguese data for a Portuguese model?
So how much actual Portuguese data was used in training this model?
According to the report the extended pre-training was a total of 107B tokens. Of those, the only clearly European Portuguese component is the 5.8B tokens from Arquivo.pt. That's around 5.5%, which is not a lot.
To be fair - there surely is some Portuguese data in the EuroLLM mixture already. But we don't know (1) how much, (2) and if it's actually European Portuguese or something else.
On the SFT side, the percentage is higher - more like 17-18%. But is that enough? To be transparent, I don't have a completely clear picture of how much European Portuguese is in total in this model. And I would like to.
Impressively, AMÁLIA beats SOTA models like Qwen 3-8B on most Portuguese benchmarks (big win!)2. But Qwen 3-8B still beats us on ALBA for example, why? Is it because they did some Portuguese specific training? Unlikely. Which makes me wonder: How much more could we benefit from additional pre-training data in Portuguese?
I can only speculate. Are we even optimizing for the right thing?
What should we be optimizing for?
The AMÁLIA team created four new benchmarks for European Portuguese. They cover a lot of ground. They focus on grammar, syntax, general knowledge, and (important!) whether it has a significant bias towards Brazilian Portuguese.
But I think there's a dimension the team missed: Are we actually measuring how much the model knows about Portugal?
It's a great opportunity to show that a model that is smaller, but has much more intrinsic knowledge about Portugal. Even when comparing with similar (or even larger) models. I don't think any of the benchmarks captures this dimension. Portuguese exams help - but don't fully solve the problem. I'm thinking: "What's the most famous dessert served in Aveiro?", "Who was the president of Portugal between 1978 and 1985?".
But I also think the best place to tackle this is the pre-training stage. This would require much more Portuguese data. And the team acknowledges that.
Final thoughts
First of all - I hesitated to write this one. I don't like to criticize anyone's work, especially on the internet. I'm happy Portugal invested in this. We have an incredibly talented team, and they deserve credit.
Second - it's very challenging to make a LARGE language model for such a TINY country and "language". The data is limited, but it's out there, we just need to get creative on how we find it.
Third - this is a good first step towards an exciting direction. The future is bright for European Portuguese LLMs! We just need to keep our minds, weights, data, and evals - open.