Monitoring ML models with FastAPI and Evidently AI
🎧 Listen
I've deployed a good amount of ML models to production. For many, deployment to production is the last step of the process. Once that's done, work is done. This is far from true. Once your model is out there, problems will start to arise. Some predictions will be wrong. Some labels will occur more often than they should, and some examples will surprise the model.
Setting up the right lenses & triggers into your model is critical. It helps to ensure everything is running smoothly, or to know when issues need to be tackled. Let's open up the black box.
Setting up FastAPI
I've previously written about how to serve your ML model with FastAPI. Let's assume we're serving our model with FastAPI and our src folder looks something like:
src
├── __init__.py
├── api <- your Fast API folder
│ ├── __init__.py
│ ├── models.py
│ └── main.py
├── pipeline
│ ├── __init__.py
│ ├── ...
│ └── train.py
└── setup.py
The main.py file is where our views are defined. Below, our main file, with a /predict endpoint, that serves predictions.
# app.py
from typing import Optional
from fastapi import FastAPI
from src.pipeline import get_prediction_for
from .models import Result, Item
import joblib
# create FastAPI app and load model
app = FastAPI()
model = joblib.load("model.joblib")
# create an endpoint that receives POST requests
@app.post("/predict/", reponse_model=Result)
def predict(features: Item):
# some processing
prediction = get_prediction_for(features)
return prediction
Prerequisite: Storing all predictions
To monitor our model, we must first make sure two things are happening:
- Prediction logging: We're actively logging all predictions our model is making
- Access to a reference dataset: We have access to the dataset where our model was trained (e.g., the training data)
Logging all predictions your model makes can be done using some managed database service (e.g., think Aurora, BigQuery, etc.). Ideally, we want to do this without increasing our prediction latency.
Fortunately, Fast API provides gives a great tool to do this: BackgroundTasks. We start by creating a function that saves our data (in this example, to BigQuery):
# monitoring.py
# ...
def save_to_database(input: Item, result: Result) -> None:
"""
Saves input/output dicts to bigquery
"""
client = BigQuery.client()
table = "your_cool_bq_table"
current_time = datetime.datetime.now()
rows_to_insert = [(current_time, input.json(), result.json())]
errors = client.insert_rows(table,
rows_to_insert)
if errors:
logging.info(f"Error: {str(errors)}")
return
logging.info("Saved prediction")
We can now add it to our API as a background task:
# app.py
# ...
from fastapi import FastAPI, BackgroundTasks
from .monitoring import save_to_database
# ...
# create an endpoint that receives POST requests
@app.post("/predict/",
reponse_model=Result,
background_tasks: BackgroundTasks)
def predict(features: Item):
# some processing
prediction = get_prediction_for(features)
background_tasks.add_task(save_to_bq, input=features, result=prediction)
return prediction
Notice how the background task does not block the prediction time. Allowing us to keep prediction latency as low as possible, while still, saving all predictions.
Setting up the monitoring
Evidently is a great open-source tool that allows you to set up monitoring for your ML models. It's not the only one, there's a myriad of them, actually. nannyML is another one.
Evidently allows you to generate a bunch of different reports you can generate. In this example, I'll focus on the Data Drift dashboard.
The Data Drift dashboard allows you to measure the difference in distribution between the predictions you are making, and the labels of your training set. When these two start to become significantly different, you are likely encountering some drift.
Alright, let's build it. We start by creating a couple of functions in our monitoring.py module:
# ... rest of the monitoring.py
DATA_WINDOW_SIZE = 3000 # how many predictions to load
# loads our training/reference dataset
def load_train_data() -> pandas.DataFrame:
train_file = "static/train_data.csv"
train_df = pandas.read_csv(train_file)
return train_df
# loads our latest predictions
def load_last_predictions() -> pandas.DataFrame:
query = f"""
SELECT created_at, input, output
FROM `my_cool_bgq_table`
ORDER BY created_at DESC
LIMIT {DATA_WINDOW_SIZE};
"""
prediction_data = pandas.read_gbq(query=query)
return prediction_data
Now that we're able to fetch both our reference data and our past predictions, we're ready to build our Data Drift dashboard:
# ... rest of the monitoring.py
# this function generates a dashboard from our reference and prediction data
# which is then saved to a `drift.html` file
def generate_dashboard() -> str:
dasboard_name = "static/drift.html"
data_drift_dashboard = Dashboard(
tabs=[
DataDriftTab(verbose_level=0),
]
)
reference_data = load_reference_data()
current_data = load_last_predictions()
data_drift_dashboard.calculate(
reference_data=reference_data,
current_data=current_data,
column_mapping=None,
)
data_drift_dashboard.save(dasboard_name)
logger.info(f"Dashboard saved to {dasboard_name}")
return dasboard_name
Notice how we're creating our dashboard, and then saving it to a static/drift.html file. The idea is then to serve this dashboard in one of our FastAPI endpoints.
Monitoring dashboard
Let's serve our data drift dashboard:
from .monitoring import generate_dashboard
# ... rest of the main.py
@app.get("/monitoring", tags=["Other"])
def monitoring():
dashboard_location = generate_dashboard()
return FileResponse(dashboard_location)
Every time we visit /monitoring, Fast API will run the generate_dashboard function, and return an html file:
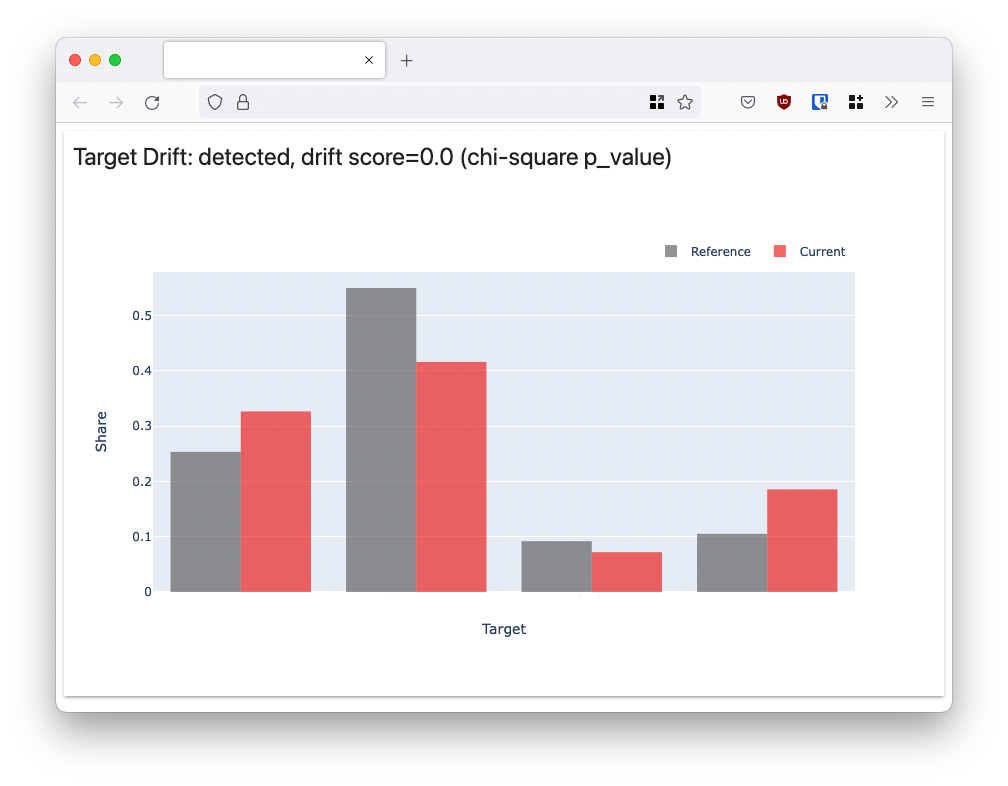
As you can see, this dashboard compares the distribution of our reference and current dataset. The current dataset being the latest Y predictions we've made.
Closing thoughts
I've found this to be a relatively straightforward way of adding a bit of visibility to what's really happening in my production models. If those distributions are looking particularly skewed: you know it's time to act.
Evidently allows us to generate much more than just a data drift dashboard. You can also generate dashboards to monitor data quality, the performance of a regression, classification performance, and many more. It's worth taking a look at their docs to see what fits your use case best.
There's a way we could increase the speed here. Instead of computing the entire dashboard every time we visit /monitoring, we could compute it every X time period in the background. This would result in much faster response from the /monitoring endpoint.
Is this dashboard enough to make sure everything is going well in production? No. But it's a great first step towards figuring out what's really going on.
Updates & notes
- This post was republished by the MLOps Community blog
- I also wrote a more general post on how to monitor machine learning APIs